Mapreduce
MapReduce es un modelo de programación utilizado en Hadoop para procesar y analizar grandes conjuntos de datos distribuidos en un clúster de computadoras. Las fases de MapReduce se dividen principalmente en dos pasos: Map y Reduce.
La fase map estudia el problema, lo divide en trozos y los manda a diferentes máquinas para que todos los trozos puedan ejecutarse concurrentemente.
Los resultados de este proceso paralelo se recogen y se distribuyen a través de un distintos servidores que ejecutan una función “reduce”, que toma los resultados de los trozos y los recombina para obtener una respuesta simple
Fase: Map
Section titled “Fase: Map”Es la primera etapa del proceso y se encarga de transformar los datos de entrada en pares clave-valor.
- División de Datos: La entrada se divide en fragmentos más pequeños llamados “splits”. Cada split se asigna a un mapper.
- Operación de Mapeo: El mapper aplica una función de mapeo a cada elemento del split, generando pares clave-valor. La clave identifica el dato y el valor es el resultado de la operación de mapeo.
- Los programas Map Reduce se dividenen Mappers, tareas que se ejecutan en los nodos
- Cada tarea MAP ataca a un solo bloque de datos HDFS
- Se ejecuta en el nodo donde reside el bloque (salvo excepciones)
Fase: Shuffle y Sort
Section titled “Fase: Shuffle y Sort”Después de la fase Map, los resultados intermedios se agrupan según sus claves. Los datos con la misma clave se agrupan juntos y se envían a la fase Reduce. Además, se realiza un proceso de ordenamiento para facilitar el trabajo de la fase Reduce.
- Ordena y consolida los datos intermedios (temporales) que generan los mappers
- Se lanzan después de que todos los mappers hayan terminado y antes de que se lancen los procesos Reduce
Fase: Reduce
Section titled “Fase: Reduce”- Reduce: En esta fase, los datos agrupados se pasan a una función de reducción (función Reduce). Esta función procesa los datos y realiza las operaciones finales. La salida de esta fase es el resultado final del procesamiento.
- Output: El resultado final después de la fase Reduce se almacena en el sistema de archivos Hadoop o se utiliza para futuros análisis, según los requisitos del usuario.
Ejemplo con más detalle
En la fase Map, se divide y transforma la entrada en pares clave-valor, mientras que en la fase Reduce, se procesan y combinan estos pares para producir el resultado final. La fase Shuffle y Sort es crucial para organizar los datos intermedios y asegurar que los datos con la misma clave se envíen al mismo proceso Reduce. Estas fases son esenciales para manejar eficientemente grandes conjuntos de datos distribuidos en un entorno de clúster.
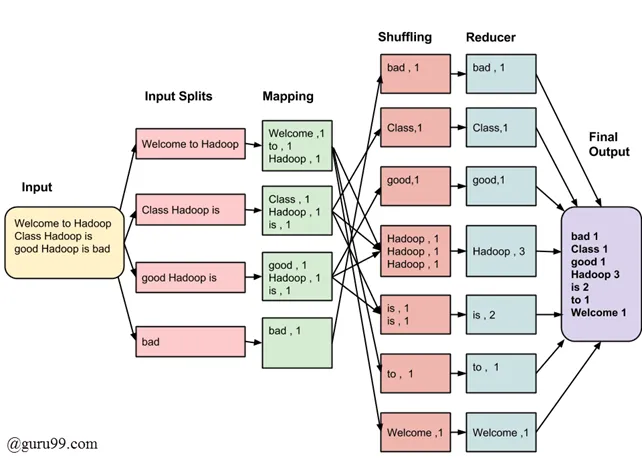
https://www.guru99.com/introduction-to-mapreduce.html
Paso a paso
Section titled “Paso a paso”Tenemos 3 documentos y vamos a contar las repeticiones de palabras:
- Documento 1: “Hadoop es un framework para procesamiento distribuido.”
- Documento 2: “MapReduce es una parte integral de Hadoop.”
- Documento 3: “El procesamiento distribuido permite manejar grandes conjuntos de datos.”
Fase MAP
Section titled “Fase MAP”En esta fase, cada documento se divide en palabras y se asigna una clave a cada palabra con un valor de 1. Esto es lo que haría la función Map.
Documento 1:
(Hadoop, 1)(es, 1)(un, 1)(framework, 1)(para, 1)(procesamiento, 1)(distribuido, 1)Documento 2:
(MapReduce, 1)(es, 1)(una, 1)(parte, 1)(integral, 1)(de, 1)(Hadoop, 1)Documento 3:
(El, 1)(procesamiento, 1)(distribuido, 1)(permite, 1)(manejar, 1)(grandes, 1)(conjuntos, 1)(de, 1)(datos, 1)Fase Shuffle - Sort
Section titled “Fase Shuffle - Sort”Los pares clave-valor se agrupan según la clave y se ordenan para facilitar la fase Reduce.
(conjuntos, [1])(datos, [1, 1])(de, [1, 1, 1])(distribuido, [1, 1])(El, [1])(es, [1, 1])(framework, [1])(grandes, [1])(Hadoop, [1, 1])(integral, [1])(manejar, [1])(MapReduce, [1])(para, [1])(parte, [1])(permite, [1])(procesamiento, [1, 1])(un, [1])(una, [1])Fase Reduce
Section titled “Fase Reduce”Se suman los valores para cada clave, produciendo el resultado final.
(conjuntos, 1)(datos, 3)(de, 3)(distribuido, 2)(El, 1)(es, 2)(framework, 1)(grandes, 1)(Hadoop, 2)(integral, 1)(manejar, 1)(MapReduce, 1)(para, 1)(parte, 1)(permite, 1)(procesamiento, 2)(un, 1)(una, 1)Ejemplos
Section titled “Ejemplos”Ejemplo 1: Contador de palabras
Section titled “Ejemplo 1: Contador de palabras”Supongamos que tienes un conjunto de datos de palabras en varios documentos y quieres contar cuántas veces aparece cada palabra. El proceso de mapeo podría ser algo así:
Entrada (fragmento de datos):
Hadoop es un framework, Hadoop procesa grandes conjuntos de datosOperación de Mapeo: Para cada palabra en el fragmento, el mapper emite pares clave-valor. Por ejemplo:
(Hadoop, 1)(es, 1)(un, 1)(framework, 1)(Hadoop, 1)(procesa, 1)(grandes, 1)(conjuntos, 1)(de, 1)(datos, 1)Salida (conjunto intermedio): Las claves se agrupan, y los valores asociados a cada clave se colocan en una lista.
(Hadoop, [1, 1])(es, [1])(un, [1])(framework, [1])(procesa, [1])(grandes, [1])(conjuntos, [1])(de, [1])(datos, [1])La fase Map genera este conjunto intermedio de pares clave-valor, que luego se utiliza en la fase Shuffle y Sort antes de pasar a la fase Reduce. Este proceso de mapeo se realiza de forma paralela en múltiples nodos del clúster, lo que permite un procesamiento eficiente de grandes conjuntos de datos.
Ejemplo 2: Análisis de Registros de Acceso a un Servidor Web
Section titled “Ejemplo 2: Análisis de Registros de Acceso a un Servidor Web”Supongamos que tienes registros de acceso a un servidor web en el siguiente formato:
Registro 1: /pagina1Registro 2: /pagina2Registro 3: /pagina1Registro 4: /pagina3Registro 5: /pagina2Registro 6: /pagina1Operación de Mapeo: El objetivo es contar cuántas veces se ha visitado cada página. Cada registro de acceso se procesaría individualmente en un mapper, y la operación de mapeo generaría pares clave-valor. En este caso, la URL de la página sería la clave, y el valor sería 1 para indicar una visita.
(/pagina1, 1)(/pagina2, 1)(/pagina1, 1)(/pagina3, 1)(/pagina2, 1)(/pagina1, 1)Salida intermedia, sort, shuffle
(/pagina1, [1, 1, 1])(/pagina2, [1, 1])(/pagina3, [1])Fase Reduce (Operación de Reducción): En la fase Reduce, se sumarían los valores asociados a cada clave para obtener el recuento total de visitas por página.
(/pagina1, 3)(/pagina2, 2)(/pagina3, 1)Ejemplo 3: Ejemplo: Cálculo del Saldo Total por Cuenta
Section titled “Ejemplo 3: Ejemplo: Cálculo del Saldo Total por Cuenta”Supongamos que tienes registros de transacciones financieras con el siguiente formato:
Transacción 1: Cuenta_A, 100.00Transacción 2: Cuenta_B, 50.00Transacción 3: Cuenta_A, -20.00Transacción 4: Cuenta_B, 30.00Transacción 5: Cuenta_A, 50.00Operación de Mapeo: El objetivo es calcular el saldo total por cuenta. Cada registro de transacción se procesaría individualmente en un mapper. La operación de mapeo generaría pares clave-valor, donde la clave es el nombre de la cuenta y el valor es el monto de la transacción (puede ser negativo para las transacciones de débito).
(Cuenta_A, 100.00)(Cuenta_B, 50.00)(Cuenta_A, -20.00)(Cuenta_B, 30.00)(Cuenta_A, 50.00)Salida Intermedia (Después de la fase Shuffle y Sort):
(Cuenta_A, [100.00, -20.00, 50.00])(Cuenta_B, [50.00, 30.00])Fase Reduce (Operación de Reducción): En la fase Reduce, se sumarían los valores asociados a cada clave para obtener el saldo total por cuenta.
(Cuenta_A, 130.00)(Cuenta_B, 80.00)Ejemplo 4: Encontrar la Temperatura Máxima por Ubicación
Section titled “Ejemplo 4: Encontrar la Temperatura Máxima por Ubicación”Supongamos que tienes registros de temperatura con el siguiente formato:
Registro 1: Ubicacion_A, 25.5°CRegistro 2: Ubicacion_B, 28.3°CRegistro 3: Ubicacion_A, 27.8°CRegistro 4: Ubicacion_B, 30.2°CRegistro 5: Ubicacion_A, 26.0°COperación de Mapeo: El objetivo es encontrar la temperatura máxima para cada ubicación. Cada registro de temperatura se procesaría individualmente en un mapper. La operación de mapeo generaría pares clave-valor, donde la clave es la ubicación y el valor es la temperatura.
(Ubicacion_A, 25.5°C)(Ubicacion_B, 28.3°C)(Ubicacion_A, 27.8°C)(Ubicacion_B, 30.2°C)(Ubicacion_A, 26.0°C)Salida Intermedia (Después de la fase Shuffle y Sort):
(Ubicacion_A, [25.5°C, 27.8°C, 26.0°C])(Ubicacion_B, [28.3°C, 30.2°C])Fase Reduce (Operación de Reducción): En la fase Reduce, se encontraría la temperatura máxima para cada ubicación.
(Ubicacion_A, 27.8°C)(Ubicacion_B, 30.2°C)Ejemplo 5: Cálculo del Tiempo Total por Usuario en una Plataforma en Línea
Section titled “Ejemplo 5: Cálculo del Tiempo Total por Usuario en una Plataforma en Línea”Datos de Entrada:
Registro 1: Usuario_A, Inicio_Sesión, 2023-01-01 08:00:00Registro 2: Usuario_A, Acción, 2023-01-01 08:15:00Registro 3: Usuario_B, Inicio_Sesión, 2023-01-01 09:30:00Registro 4: Usuario_A, Fin_Sesión, 2023-01-01 09:35:00Registro 5: Usuario_B, Acción, 2023-01-01 10:00:00Operación de Mapeo: El objetivo es calcular el tiempo total que cada usuario ha pasado en la plataforma. Cada registro de actividad se procesaría individualmente en un mapper. La operación de mapeo generaría pares clave-valor, donde la clave es el nombre del usuario y el valor es la duración de la actividad (por ejemplo, tiempo entre el inicio de sesión y la acción o entre la acción y el cierre de sesión).
(Usuario_A, 15 minutos)(Usuario_B, 30 minutos)(Usuario_A, 80 minutos)Salida Intermedia (Después de la fase Shuffle y Sort):
(Usuario_A, [15 minutos, 80 minutos])(Usuario_B, [30 minutos])Fase Reduce (Operación de Reducción): En la fase Reduce, se sumarían los tiempos asociados a cada usuario para obtener el tiempo total que cada usuario ha pasado en la plataforma.
(Usuario_A, 95 minutos)(Usuario_B, 30 minutos)Ejemplo 6: Identificación de Usuarios Influyentes en una Red Social
Section titled “Ejemplo 6: Identificación de Usuarios Influyentes en una Red Social”Datos de Entrada:
Evento 1: Usuario_A publicó un mensaje.Evento 2: Usuario_B comentó en el mensaje de Usuario_A.Evento 3: Usuario_C dio "Me gusta" al mensaje de Usuario_A.Evento 4: Usuario_A compartió el mensaje de Usuario_B.Evento 5: Usuario_C comentó en el mensaje compartido por Usuario_A.Evento 6: Usuario_B dio "Me gusta" al comentario de Usuario_C.Operación de Mapeo: El objetivo es identificar patrones de interacción entre usuarios. Cada evento se procesaría individualmente en un mapper. La operación de mapeo generaría pares clave-valor, donde la clave es el nombre del usuario y el valor es la acción realizada.
Salida mapeo
(Usuario_A, [publicó, compartió])(Usuario_B, [comentó, dio_me_gusta])(Usuario_C, [dio_me_gusta, comentó])(Usuario_A, [compartió])(Usuario_C, [comentó, dio_me_gusta])(Usuario_B, [dio_me_gusta])Salida Intermedia (Después de la fase Shuffle y Sort):
(Usuario_A, [publicó, compartió, compartió])(Usuario_B, [comentó, dio_me_gusta, dio_me_gusta])(Usuario_C, [dio_me_gusta, comentó, comentó])Fase Reduce (Operación de Reducción): En la fase Reduce, se analizarían los patrones de interacción para determinar la influencia de cada usuario. Por ejemplo, podrías asignar puntajes a los usuarios según el número de publicaciones, comentarios y “Me gusta” recibidos, y luego sumar esos puntajes para cada usuario.
(Usuario_A, Puntaje: 3)(Usuario_B, Puntaje: 3)(Usuario_C, Puntaje: 3)Ejemplo 7: Detección de Anomalías en Datos de Sensores Industriales
Section titled “Ejemplo 7: Detección de Anomalías en Datos de Sensores Industriales”Datos de Entrada:
Evento 1: Sensor_A, Temperatura, 30°CEvento 2: Sensor_B, Presión, 100 psiEvento 3: Sensor_A, Temperatura, 32°CEvento 4: Sensor_B, Presión, 105 psiEvento 5: Sensor_A, Temperatura, 28°CEvento 6: Sensor_B, Presión, 110 psiOperación de Mapeo: El objetivo es identificar patrones de comportamiento anómalo en los datos del sensor. Cada evento se procesaría individualmente en un mapper. La operación de mapeo generaría pares clave-valor, donde la clave es el tipo de sensor y el valor es el valor del evento.
Salida mapeo:
(Sensor_A, [30°C, 32°C, 28°C])(Sensor_B, [100 psi, 105 psi, 110 psi])Salida Intermedia (Después de la fase Shuffle y Sort):
(Sensor_A, [30°C, 32°C, 28°C])(Sensor_B, [100 psi, 105 psi, 110 psi])Fase Reduce (Operación de Reducción): En la fase Reduce, se analizarían los patrones de comportamiento para identificar anomalías. Por ejemplo, podrías calcular estadísticas como el promedio y la desviación estándar para cada tipo de sensor y luego identificar eventos que se desvíen significativamente de estas estadísticas como posibles anomalías.
(Sensor_A, Promedio: 30°C, Desviación Estándar: 2°C, Anomalías: [32°C, 28°C])(Sensor_B, Promedio: 105 psi, Desviación Estándar: 5 psi, Anomalías: [110 psi])Ejercicio Ventas ✏️
Section titled “Ejercicio Ventas ✏️”Para comprender mejor cómo funciona un trabajo típico de Hadoop basado en MapReduce, vamos a emularlo con un script en Python.
Hadoop funciona de forma nativa con Java pero cuenta con una herramienta que permite la ejecución de programas/scripts en diferentes lenguajes como python. Esta es la herramienta “Streaming”: https://hadoop.apache.org/docs/stable/hadoop-streaming/HadoopStreaming.html
Este ejemplo trabaja con un conjunto de datos relacionados con las ventas de una empresa con múltiples tiendas: purchases.txt
Lo puedes descargar en: https://github.com/josepgarcia/datos
##Extracto del archivo
2012-01-01 09:00 San Jose Men's Clothing 214.05 Amex2012-01-01 09:00 Fort Worth Women's Clothing 153.57 Visa2012-01-01 09:00 San Diego Music 66.08 Cash2012-01-01 09:00 Pittsburgh Pet Supplies 493.51 Discover2012-01-01 09:00 Omaha Children's Clothing 235.63 MasterCard2012-01-01 09:00 Stockton Men's Clothing 247.18 MasterCard2012-01-01 09:00 Austin Cameras 379.6 Visa2012-01-01 09:00 New York Consumer Electronics 296.8 Cash2012-01-01 09:00 Corpus Christi Toys 25.38 Discover2012-01-01 09:00 Fort Worth Toys 213.88 VisaObjetivo: Calcular el importe total de ventas para cada tienda (la tienda aparece en la tercera columna del fichero).
El paradigma MapReduce tiene 3 fases:
- mapper()
- shuffle - sort
- reducer()
Fase 1: Mapper
Section titled “Fase 1: Mapper”En la fase mapper , procesamos cada línea del fichero y extraemos un par clave-valor: el nombre de la tienda como clave y el importe de la venta como valor (tercera y quinta columna).
Tu tarea: Crea un script en Python llamado mapper.py que lea el archivo y, por cada línea, imprima el nombre de la tienda y el importe separados por tabulador.
# Ejemplo de salida esperada:San José 214,05Fort Worth 153,57...Fort Worth 213,88# Lo ejecutamos y guardamos la salida$ python3 mapper.py > salida_mapper.csvFase 2: sort - shuffler
Section titled “Fase 2: sort - shuffler”En esta fase, los pares clave-valor generados por el mapper se ordenan alfabéticamente por el nombre de la tienda, para que todas las ventas de una misma tienda se agrupen juntas.
La sustituiremos por el comando sortdel sistema:
$ cat salida_mapper.csv | sort > salida_sort.csvFase 3: reducer
Section titled “Fase 3: reducer”El reducer es responsable de sumar los importes de venta para cada tienda. Partimos de un fichero ordenado, lo que permite procesar los datos secuencialmente y detectar fácilmente los cambios de tienda.
Tu tarea: Crea un script en Python llamado reducer.py que lea el archivo ordenado y vaya sumando los importes de cada tienda. Al detectar un cambio de tienda, escribe la suma total para la tienda anterior POR PANTALLA (no es necesario guardar ningún dato en un array o similar) y comienza la suma para la nueva tienda.
$ cat salida_sort.csv
Albuquerque 440.7Anchorage 22.36Anchorage 298.86Anchorage 368.42Anchorage 390.2Anchorage 6.38Atlanta 254.62Ejemplo de salida esperada:
Albuquerque 440.7Anchorage 1086.22Atlanta 254.62...Tuberias
Section titled “Tuberias”Para que funcione el programa a través de hadoop, necesitamos que nuestro script pueda trabajar con tuberías (pipes) no de ficheros tal y como lo hace ahora.
Modifica el código para que en vez de leer de ficheros, tus scripts lean del stream de entrada.
cat purchases.txt | python mapper.py | sort | python reducer.py > salida.txtMejoras
Section titled “Mejoras”- Todas las líneas del archivo de entrada deben tener el mismo número de campos, si no es así en alguna línea hay que descartarla.
- Asegúrate que el valor numérico sea float.
- Como se ha mencionado anteriormente, hay que tener en cuenta que al reducer le llegan los datos ordenados.
Ejecución a través de hadoop
Section titled “Ejecución a través de hadoop”- Subir el dataset a hdfs
- Subir al contenedor hadoop los archivos .py
hadoop jar $HADOOP_HOME/share/hadoop/tools/lib/hadoop-streaming-*.jar \ -files mapper.py,reducer.py \ -input /purchases.txt \ -output /comprasxtienda \ -mapper "python3 ./mapper.py" \ -reducer "python3 ./reducer.py"
## Si el comando anterior falla:mapred streaming -files mapper.py,reducer.py -input /purchases.txt -output \ /comprasxtienda3 -mapper "python3 ./mapper.py" -reducer "python3 ./reducer.py"- Una vez ejecutado el comando, podemos ver la salida en /comprasxtienda/part-00000
- Si la ejecución es correcta existirá un archivo SUCCESS
dfs -ls /comprasxtienda-rw-r--r-- 1 hadoop supergroup 0 2024-12-05 11:11 /comprasxtienda7/_SUCCESS-rw-r--r-- 1 hadoop supergroup 1201 2024-12-05 11:11 /comprasxtienda7/part-00000Ejercicios ✏️
Section titled “Ejercicios ✏️”Ejercicio 1
Section titled “Ejercicio 1”Redefine el mapper para que mapreduce devuelva como salida las ventas totales por categoría.
Ejemplo de resultado (datos no reales):
Pet Supplies 1123.4Music 22344.56Clothing 3356.45Ejercicio 2
Section titled “Ejercicio 2”Redefine el mapper y reducer para que se obtenga la venta más alta para cada tipo de pago de las registradas en todo el archivo.
No hay que devolver las ventas totales por tipo de pago
Ejemplo de resultado (datos no reales):
Visa 133.5 -> la venta más alta de todas las hechas con visaCash 223.56 -> la venta más alta de todas las hechas con cashMastercard 1356.45 -> la venta más alta de todas las hechas con MastercardEjercicio 3
Section titled “Ejercicio 3”Realiza las modificaciones necesarias para que mapreduce nos devuelve la venta más alta de todas las realizadas
Ejercicio 4
Section titled “Ejercicio 4”Redefine los scripts para que se obtengan la suma de todas las ventass.
Ejercicio Temperatura ✏️
Section titled “Ejercicio Temperatura ✏️”Entregable en AULES, documento en PDF con el código de los scripts y los resultados.
Descarga el dataset city_temperature.csv.zip de https://github.com/josepgarcia/datos
Realiza los scripts necesarios y ejecútalos en hadoop para contestar a las siguientes preguntas:
- Temperatura más alta de cada país siempre (de todos los años). Indicar país, mes, año y temperatura.
Ejemplo de salida (datos no reales):
España 7 1980 41Francia 8 1975 43Italia 7 1990 44.....- Media anual de temperatura por región.
Ejemplo de salida (datos no reales):
Africa 43,5Europa 37,3.....- Media anual de temperatura por país y año.
Ejemplo de salida (datos no reales):
España 1975 34España 1976 35España 1977 33,5España 1978 34,8Francia 1975 33Francia 1976 34,3Francia 1977 35,6.....- Mínima temperatura por región (mostrar también qué mes y año fue).
Ejemplo de salida (datos no reales):
África 2 1980 -10Europa 3 1975 -13.....