HIVE
🚀 Presentación: HIVE
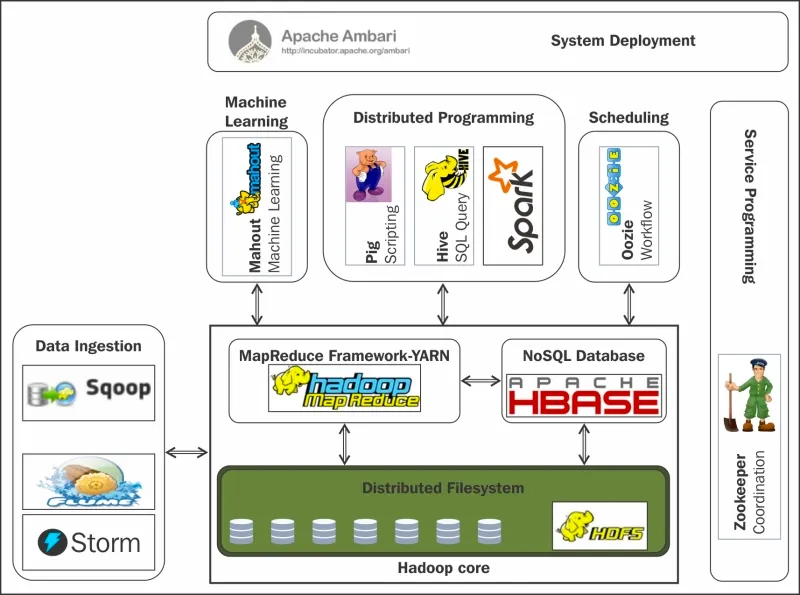
Herramienta desarrollada por Facebook y luego donada a la Apache Software Foundation.
Proporciona una interfaz de consulta similar a SQL (Structured Query Language) para interactuar con grandes conjuntos de datos almacenados en Hadoop Distributed File System (HDFS) o en otros sistemas de almacenamiento compatibles con Hadoop.
Funcionamiento:
- Metastore: Almacena información sobre el esquema de datos y las particiones en una base de datos relacional para facilitar la administración de metadatos.
- HQL (Hive Query Language): Los usuarios escriben consultas en un lenguaje similar a SQL llamado HQL para expresar las operaciones que desean realizar en los datos.
- Traducción a MapReduce: Las consultas HQL se traducen internamente en tareas MapReduce, que se ejecutan en un clúster Hadoop distribuido.
- Optimizaciones internas: Hive realiza optimizaciones para mejorar el rendimiento, como la eliminación de pasos redundantes y la reorganización eficiente de tareas MapReduce.
- Almacenamiento de datos: Los resultados de las consultas se almacenan en HDFS o en otros sistemas compatibles con Hadoop, organizados en tablas y en formatos específicos para un almacenamiento eficiente.
- Integración: Hive se integra con diversas herramientas en el ecosistema Hadoop, permitiendo a los usuarios utilizar diferentes herramientas según sus necesidades.
Componentes
Section titled “Componentes”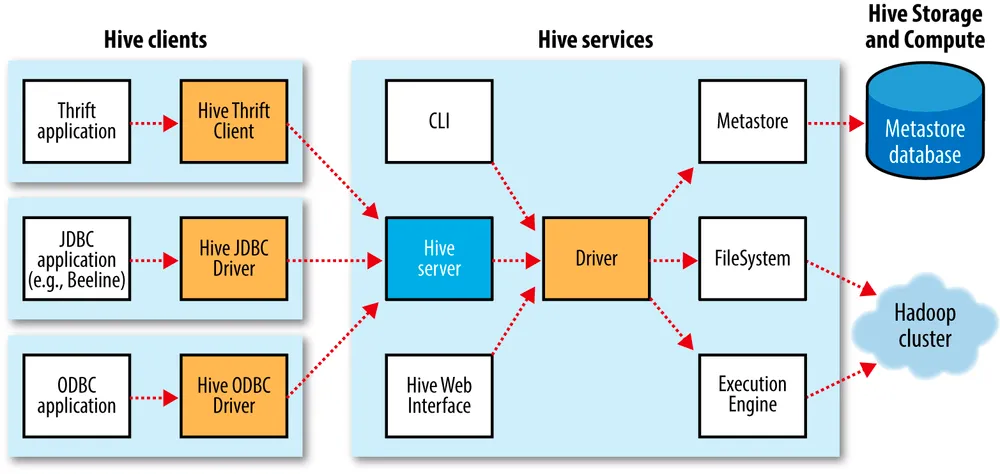
Prerrequisitos antes de iniciar
Section titled “Prerrequisitos antes de iniciar”Antes de comenzar la instalación de Hive, verifica que tienes:
- Hadoop instalado y configurado (versión 2.x o 3.x)
- Java 11 instalado y configurado en
$JAVA_HOME - HDFS iniciado:
Instalación y configuración inicial
Section titled “Instalación y configuración inicial”- Descargaremos en /opt/ la versión 2.3.9 Versión compatible con el Java 11 que tenemos instalado, con la versión 3.1.3 dará error.
https://archive.apache.org/dist/hive/hive-2.3.9/apache-hive-2.3.9-bin.tar.gz
1. Descargar en /opt/wget https://archive.apache.org/dist/hive/hive-2.3.9/apache-hive-2.3.9-bin.tar.gz2. Descomprimir
3. Crear "enlace" blando llamado "hive" que apunte a la carpeta descomprimida- Añadimos HIVE_HOME a .bashrc y modificamos el PATH
## Sustituye el path si tu instalación de hive no se encuentra en este directorio
export HIVE_HOME=/opt/hiveexport PATH=$PATH:$HIVE_HOME/binDentro del directorio bin de hive podemos ver los siguientes binarios:
beeline: herramienta cliente modo comandos.hive: herramienta cliente.hiveserver2: servidor de hive.schematools: herramienta que nos permite trabajar con los metadatos de hive.
- Configuramos Hive (carpeta
confdentro de hive)
# Copiamos los siguientes templates por defecto
cp hive-default.xml.template hive-site.xmlcp hive-env.sh.template hive-env.shcp hive-exec-log4j2.properties.template hive-exec-log4j2.propertiescp hive-log4j2.properties.template hive-log4j2.propertiescp beeline-log4j2.properties.template beeline-log4j2.properties- Editamos
hive-env.shy añadimos:
export HADOOP_HOME=/opt/hadoopexport HIVE_CONF_DIR=/opt/hive/conf- Hive ataca al sistema de ficheros HDFS de Hadoop. Por lo tanto, es necesario que para trabajar con Hive creemos una serie de directorios en el HDFS.
# Dará error si ya existehdfs dfs -mkdir /tmp
# Como vamos a trabajar con el usuario hadoop# damos permisos a /tmp para que no de problemashdfs dfs -chmod g+w /tmp
# Directorio donde trabaja Hive, no cambiar de nombrehdfs dfs -mkdir -p /user/hive/warehouse
# Damos permisos para que Hive pueda trabajar aquí.# Le daremos permisos al grupo hadoop, que es el que usaremos con Hivehdfs dfs -chmod g+w /user/hive/warehouse- Añadimos al archivo hive-site.xml:
<property> <name>system:java.io.tmpdir</name> <value>/tmp/hive/java<value></property><property> <name>system:user.name</name> <value>${user.name}</value></property>→ Directorio temporal
→ Que utilice como nombre de usuario el del usuario que lo está ejecutando (en nuestro caso será hadoop), hubiésemos podido escribir en value
- Creamos una base de datos a través del cliente hive.
$ pwd/opt/hive
# Crea una carpeta y si la creación ha sido correcta entra en ella$ mkdir bbdd && cd bbdd
# Inicializamos una base de datos (un esquema)$ schematool -dbType derby -initSchema
$ lsderby.log # log de la base de datosmetastore_db # directorio de la base de datos, no tocar ficheros
# validar el schema que hemos creado, para conocer el comando por si posteriormente hay algún error$ schematool -validate -dbType -verbose## Este comando dará error, falta un parámetro
# El comando debe devolver:Starting metastore validation
Validating schema versionSucceeded in schema version validation.[SUCCESS]
Validating sequence number for SEQUENCE_TABLESucceeded in sequence number validation for SEQUENCE_TABLE[SUCCESS]
Validating metastore schema tablesSucceeded in schema table validation.[SUCCESS]
Validating database/table/partition locationsSucceeded in database/table/partition location validation[SUCCESS]
Validating columns for incorrect NULL valuesSucceeded in column validation for incorrect NULL values[SUCCESS]
Done with metastore validation: [SUCCESS]schemaTool completeddbType derby
Section titled “dbType derby”¿ Qué significa el comando: “schematool -dbType derby -initSchema”?
Utilizaremos un “gestor de base de datos” llamado “derby”, se utiliza para testing, es muy ligero. Al inicializar se crean 2 archivos (log y metastore), por eso hemos inicializado dentro de una carpeta (bbdd), para que no queden en la raíz de hive.
Otras opciones posibles serían:
schematool -dbType mysql -initSchemaschematool -dbType postgres -initSchemaschematool -dbType oracle -initSchemaschematool -dbType mssql -initSchema- Atacamos el metastore con el cliente hive
[!WARNING] ATENCIÓN Para ejecutar hive debemos estar en la carpeta de la bbdd que hemos creado anteriormente, a esta carpeta la hemos llamado bbdd y tenía los metadatos para dbType “derby”
[!TIP] BASE DE DATOS DEFAULT Al iniciar Hive, si no seleccionas ninguna base de datos, estarás conectado por defecto a la base de datos
default. Puedes crear tablas directamente ahí sin necesidad de crear una nueva base de datos explícitamente.
$ hive
....
hive> create database ejemplo;show databases;use ejemplo;show tables;
create table if not exists t1 (name string);
show tables;- Vamos a la página de hadoop (puerto 9870) y localizamos la base de datos.
- Insertamos una fila
insert into t1 values ('Mi nombre');
select * from t1;start-yarn.sh
- Creamos otra tabla e insertamos otro registro
create table if not exists t2 ( codigo integer);
Insert into t2 values (10);select * from t2;✅ Ejercicio: instalación y configuración.
- Muestra el contenido de las tablas a través de la web de HDFS y realiza una captura de pantalla.
- Muestra el contenido de las tablas a través de la consola, con el comando hdfs y realiza una captura de pantalla.
Comandos
Section titled “Comandos”



Tablas (tipos)
Section titled “Tablas (tipos)”Tablas Internas
Section titled “Tablas Internas”- Son gestionadas completamente por Hive.
- Los datos y la estructura están bajo el control total de Hive, incluyendo la eliminación de datos cuando se elimina la tabla.
CREATE TABLE empleados ( id INT, nombre STRING, salario DOUBLE);Tablas Externas
Section titled “Tablas Externas”- Hive gestiona solo la estructura de metadatos, pero los datos residen fuera de Hive.
- Los datos NO se eliminan automáticamente cuando se elimina la tabla en Hive.
CREATE EXTERNAL TABLE empleados_externos ( id INT, nombre STRING, salario DOUBLE)LOCATION '/ruta/en/hadoop/datos/empleados';En ambos casos, estas tablas pueden ser consultadas y utilizadas en consultas SQL dentro de Hive, pero la diferencia clave radica en la gestión de los datos y la persistencia.
Tablas: Internas vs Externas
Section titled “Tablas: Internas vs Externas”| Característica | Tablas Internas (MANAGED) | Tablas Externas (EXTERNAL) |
|---|---|---|
| Gestión de datos | Hive controla datos y metadatos | Hive solo controla metadatos |
| Al hacer DROP | Se eliminan datos y metadatos | Solo se eliminan metadatos |
| Ubicación de datos | /user/hive/warehouse (por defecto) | Ubicación especificada con LOCATION |
| Casos de uso | Datos exclusivos de Hive, ETL temporales | Datos compartidos, fuentes externas (S3, Azure) |
| Optimización | Hive puede reorganizar datos | Los datos permanecen en formato original |
Casos de uso recomendados
Section titled “Casos de uso recomendados”Usa tablas INTERNAS cuando:
- Los datos son generados y consumidos exclusivamente por Hive
- Necesitas garantías de integridad y consistencia
- Quieres aprovechar optimizaciones automáticas de Hive
- Los datos son temporales (staging, pruebas)
Usa tablas EXTERNAS cuando:
- Los datos son compartidos con otras herramientas (Spark, Pig, etc.)
- Los datos provienen de sistemas externos (logs, S3, Azure Data Lake)
- No quieres que Hive elimine los datos al borrar la tabla
- Los datos están en formatos específicos (Parquet, ORC, Avro) y no quieres duplicarlos
Ejemplo tablas Internas
Section titled “Ejemplo tablas Internas”Nos creamos un fichero plano con una nueva terminal.
cd /tmp/hadoop
vi empleados.txtRosa,50Pedro,60Raul,56Maria,35Vamos a la terminal conectada a Hive y la base de datos ejemplo. Creamos una nueva tabla empleados especificando que la cargaremos de fichero especificando que esta formateadas por filas y separadas por comas.
hive>create table empleados(nombre string,edad integer)row format delimitedfields terminated by ',';load data local inpath '/tmp/hadoop/empleados.txt' into table empleados;Volvemos a repetir la creación de otro fichero (p.e. copiando los datos del anterior) y lo cargamos en Hive. Veremos que Hive lo guarda todo como ficheros en el directorio correspondiente de hdfs.
load data local inpath '/tmp/hadoop/empleados2.txt' into table empleados;## (local especifica que busca el fichero en la maquina local)Podemos realizar búsquedas:
select * from empleados where edad > 50;** Accedemos a web HDFS para ver cómo ha importado los archivos) **
Si ahora borramos la tabla con Hive. Veremos cómo desaparece tanto la tabla como los ficheros en HDFS. Es el propio Hive quien gestiona los datos a todos los niveles.
drop table empleados;[!NOTE] IMPORTANTE Fíjate que hemos usado
LOAD DATA LOCAL INPATH. La palabra clave LOCAL indica a Hive que debe buscar el archivo en el sistema de archivos de tu máquina (Linux) y copiarlo a HDFS (al directorio de la tabla). Si no pusiéramos LOCAL, Hive buscaría el archivo en HDFS y lo movería a la tabla.
Ejemplo tablas Externas
Section titled “Ejemplo tablas Externas”Vamos a subir el fichero de empleados a través de hdfs.
hdfs dfs -mkdir /pruebahdfs dfs -put empleados.txt /pruebaCreamos la tabla como external y especificando la localización. Visualizaremos como crea automáticamente el directorio en el sistema hdfs. Luego cargamos la información del fichero.
create external table empleados(nombre string,edad integer)row format delimitedfields terminated by ','location '/user/hive/datos/empleados';location: dónde vamos a tener los datos.
** Entrar en webdfs para ver que se ha creado un directorio llamado datos en la carpeta que hemos indicado.
Cargamos los datos:
load data inpath '/prueba/empleados.txt' into table empleados;Ahora ya podemos ver el fichero desde webdfs.
Lo más importante de las tablas externas, es que cuando hacemos ahora un drop de la tabla, el fichero no desaparece en hdfs.
Aclaración sobre la carga de datos (Local vs HDFS)
Section titled “Aclaración sobre la carga de datos (Local vs HDFS)”Es común la confusión sobre dónde debe estar el archivo. En Hive tienes tres formas principales de “cargar” datos:
-
LOAD DATA LOCAL INPATH 'ruta_linux' ...:- Origen: Tu sistema de archivos local (Linux).
- Acción: COPIA el archivo al directorio de la tabla en HDFS (sea interna o externa).
- Uso: Cuando tienes el archivo en tu máquina y quieres subirlo a Hive.
-
LOAD DATA INPATH 'ruta_hdfs' ...(Sin LOCAL):- Origen: Una ruta existente en HDFS.
- Acción: MUEVE el archivo desde la ruta origen HDFS al directorio de la tabla en HDFS.
- Uso: Cuando el archivo ya está en HDFS (p.e. dejado por otro proceso) y quieres que pase a formar parte de la tabla.
-
LOCATION 'ruta_hdfs'(Solo Tablas Externas):- Origen: Una ruta existente en HDFS.
- Acción: No mueves ni copias nada. Simplemente le dices a Hive “la tabla mira a esta carpeta”.
- Uso: La forma más pura de tabla externa. Dejas los archivos en HDFS (con
hdfs dfs -puto Spark) y creas la tabla apuntando ahí. No necesitas ejecutarLOAD DATA.
En el ejemplo anterior de tabla externa, combinamos métodos: primero subimos el archivo a una carpeta temporal en HDFS (/prueba) y luego usamos LOAD DATA INPATH para moverlo a la carpeta final de la tabla externa (/user/hive/datos/empleados).
drop table empleados;Podemos ver que aún existen el webdfs.
Práctica empleados
Section titled “Práctica empleados”Preparar datos
Section titled “Preparar datos”Utilizando la librería de python faker, crea un archivo con 1000 datos de empleados que tenga la siguiente estructura:
$ cat empleados.txtMichael|Montreal,Toronto|Male,30|DB:80|Product:Developer:LeadWill|Montreal|Male,35|Perl:85|Product:Lead,Test:LeadShelley|New York|Female,27|Python:80|Test:Lead,COE:ArchitectLucy|Vancouver|Female,57|Sales:89,HR:94|Sales:LeadTablas internas
Section titled “Tablas internas”- Comprobar si existe la base de datos empleados_internal
- Creamos una base de datos llamada empleados_internal
- Nos conectamos a ella para poder utilizarla
- Creamos una tabla
CREATE TABLE IF NOT EXISTS empleados_internal( name string, work_place ARRAY<string>, sex_age STRUCT<sex:string,age:int>, skills_score MAP<string,int>, depart_title MAP<STRING,ARRAY<STRING>>)COMMENT 'This is an internal table'ROW FORMAT DELIMITEDFIELDS TERMINATED BY '|'COLLECTION ITEMS TERMINATED BY ','MAP KEYS TERMINATED BY ':'- La cargamos con los datos del fichero empleados.txt
- Hacemos un SELECT de los datos.
- Comprobar que existe el directorio warehouse de HIVE, dentro de la bd empleados.
Tablas externas
Section titled “Tablas externas”- Creamos una nueva tabla, empleados_external
- Lo cargamos con los mismos datos.
- Hacemos un SELECT de los datos
- Hacer una SELECT para buscar a la empleada X (un nombre de empleada que exista)
- Borrar las dos tablas
- Comprobar que ha borrado la interna pero los datos de la externa permanecen.
Práctica deslizamientos de la tierra
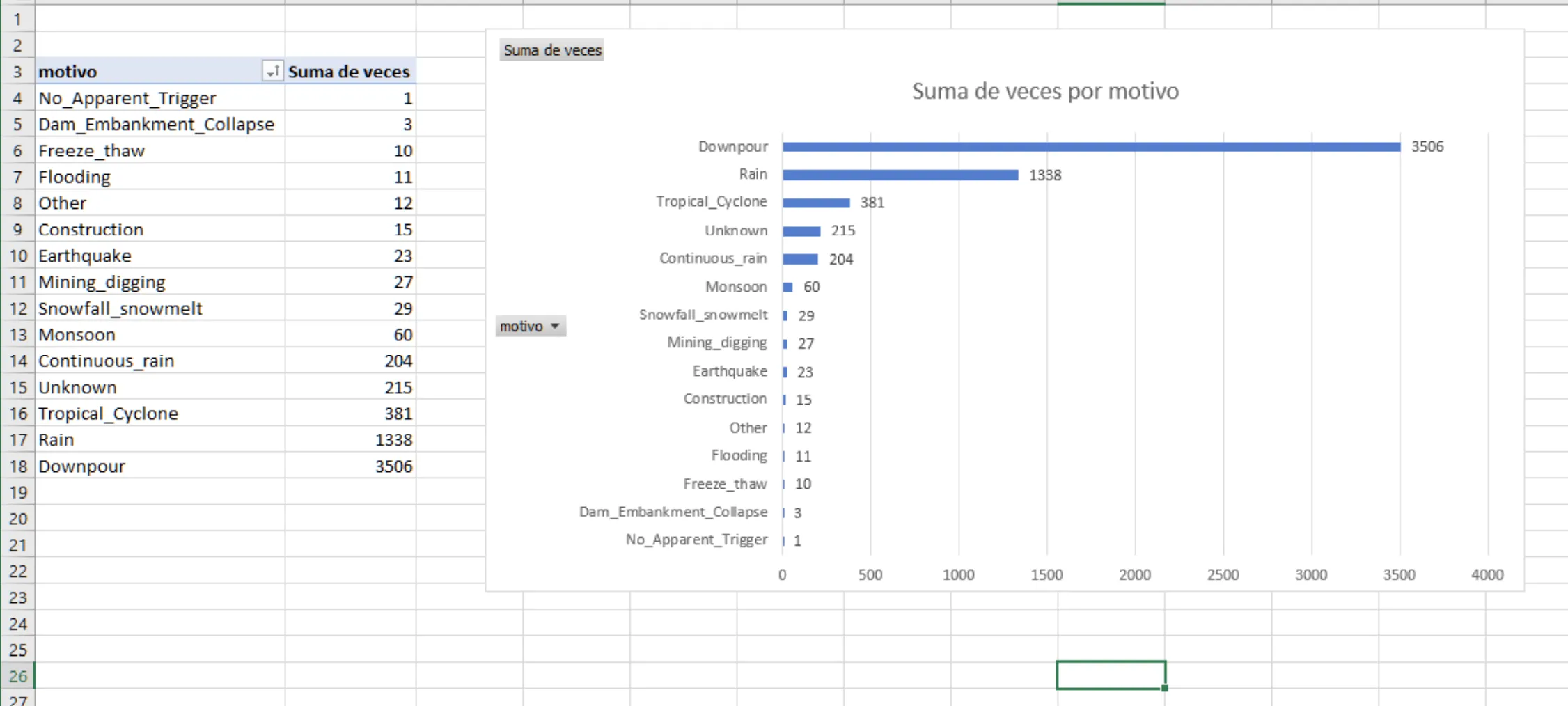
Section titled “Práctica deslizamientos de la tierra”Vamos a realizar unas cuantas SELECT contra una DataSet de la NASA, que contiene información sobre deslizamientos de tierra ocurridos alrededor del mundo. Al finalizar generaremos una tabla (google sheets o excel) en base a la consulta de datos.
https://github.com/josepgarcia/datos
El fichero deslizamientos.csv tiene los datos
Estructura de la tabla en HIVE.
create table deslizamientos(id bigint,fecha string,hora string,country string,nearest_places string,hazard_type string,landslide_type string,motivo string,storm_name string,fatalities bigint,injuries string,source_name string,source_link string,location_description string,location_accuracy string,landslide_size string,photos_link string,cat_src string,cat_id bigint,countryname string,near string,distance double,adminname1 string,adminname2 string,population bigint,countrycode string,continentcode string,key string,version string,tstamp string,changeset_id string,latitude double,longitude double,geolocation string)ROW FORMAT DELIMITEDFIELDS TERMINATED BY ';';- Carga los datos del fichero
deslizamientos.csv - “Describimos” la tabla para entender su contenido
- Contamos cuantos deslizamientos se han insertado (9563)
- Muestra el nombre y fecha de las 5 primeras filas.
- Averiguar el país, el tipo de deslizamiento y el motivo de aquellos sitios donde haya habido más de 100 víctimas.
- Averiguar los deslizamientos ocurridos por tipos de deslizamiento (landslide_type)
- Crear tabla para importar los países
countries.csv- Pista: El fichero tiene código y nombre del país. Crea la tabla
paisescon esas columnas.
- Pista: El fichero tiene código y nombre del país. Crea la tabla
- Cargar la tabla.
- Mostrar los 10 primeros países.
- Cuáles son los países 10 primeros países que tienen más movimientos registrados.
- Cantidad de deslizamientos y el motivo por Países (nombre y código)
- Exportamos la select a un fichero para importarlo con alguna herramienta (google sheets) y hacer un gráfico con el resultado.
[!TIP] EXPORTAR DATOS El comando
INSERT OVERWRITE LOCAL DIRECTORYejecuta la consulta y guarda el resultado en una carpeta de tu sistema de archivos local (Linux), en lugar de en HDFS o en una tabla Hive.
insert overwrite local directory '/tmp/datos' row format delimited fieldsterminated by ',' select a.cod,b.country,b.motivo,count(*) from paises ajoin deslizamientos b on a.nombre=b.country group by a.cod,b.country,b.motivo;Resultado final: