Streaming Facturas
Facturas: Spark streaming con ficheros
Section titled “Facturas: Spark streaming con ficheros”Este ejercicio tiene como objetivo procesar archivos JSON de facturas generados por diferentes sucursales de una empresa cada 5 minutos. Cada factura puede contener múltiples líneas de artículos, y el propósito es descomponerlas en facturas individuales.
https://github.com/josepgarcia/datos/raw/main/invoices/invoices.zip
ENTRADA: Cada archivo JSON incluye detalles de la factura, como el número de factura, la hora de creación, el ID de la tienda, el ID del punto de venta, el tipo de cliente, el método de pago, el tipo de entrega y una lista de artículos (InvoiceLineItems). SALIDA: Por cada línea de artículo en InvoiceLineItems, se generará un nuevo documento con los detalles de la factura y del artículo correspondiente.
EJEMPLO
Estructura de una de las facturas almacenadas en JSON
 A partir de la estructura anterior generaríamos 4 líneas como la siguiente:
A partir de la estructura anterior generaríamos 4 líneas como la siguiente:
 Estructura de directorios para el proyecto:
Estructura de directorios para el proyecto:
invoices/├── invoices.ipynb├── DATOS_TMP/│ ├── Invoice-set2.json│ └── Invoice-set3.json└── ENTRADA/ └── Invoice-set1.jsonFuncionamiento del programa:
- El programa monitorea continuamente la carpeta ENTRADA, donde las sucursales depositan los archivos JSON de facturas.
- Para simular la llegada de nuevos archivos, se moverán manualmente los archivos desde DATOS_TMP a ENTRADA.
- Cada 5 minutos se buscará un nuevo archivo en la carpeta ENTRADA, el programa lo procesa y guarda los datos transformados en una carpeta llamada SALIDA.
Versión inicial
Section titled “Versión inicial”La primera versión será sin “streaming”, leeremos los datos de ENTRADAlos transformaremos y los escribiremos en SALIDA
Lectura de datos
Section titled “Lectura de datos”Creamos el archivo invoices.ipynb
Iniciar una sesión de Spark y leer todos los archivos JSON de la carpeta ENTRADA.
from pyspark.sql import SparkSession
spark = SparkSession.builder.getOrCreate()raw_df = spark.read.json("./invoices/ENTRADA/*.json")
raw_df.printSchema()raw_df.show(5)Transformación
Section titled “Transformación”Seleccionar las columnas relevantes y usar la función explode para descomponer el array InvoiceLineItems en filas individuales.
explode_df = raw_df.selectExpr("InvoiceNumber", "CreatedTime", "StoreID", "PosID", "CustomerType", "PaymentMethod", "DeliveryType", "explode(InvoiceLineItems) as LineItem")explode_df.printSchema()explode_df.show(5)Renombrar las columnas anidadas para obtener una estructura plana y eliminar la columna original LineItem.
from pyspark.sql.functions import exprlimpio_df = explode_df \ .withColumn("ItemCode", expr("LineItem.ItemCode")) \ .withColumn("ItemDescription", expr("LineItem.ItemDescription")) \ .withColumn("ItemPrice", expr("LineItem.ItemPrice")) \ .withColumn("ItemQty", expr("LineItem.ItemQty")) \ .withColumn("TotalValue", expr("LineItem.TotalValue")) \ .drop("LineItem")limpio_df.printSchema()limpio_df.show(5)Guardando el resultado
Section titled “Guardando el resultado”Escribir el DataFrame transformado en la carpeta SALIDA en el formato deseado (por ejemplo, CSV, json o Parquet).
facturaWriterQuery = limpio_df.write \ .format("json") \ .mode("overwrite") \ .option("path", "./invoices/salidatmp.json") \ .save()
facturaWriterQuery = limpio_df.write.mode("overwrite").parquet("./invoices/SALIDA/")Modificando para streaming
Section titled “Modificando para streaming”✅ Ejercicio: Adapta el programa para el procesamiento en tiempo real.
Es necesario realizar ajustes que permitan que el programa permanezca a la espera de nuevos archivos en la carpeta ENTRADA. Esto se logra modificando las operaciones de lectura y escritura para que funcionen en modo streaming.
Modificaciones en la lectura (READ)
- Uso de readStream: Para leer datos en modo streaming, se debe utilizar la función readStream en lugar de read.
Modificaciones en la escritura (WRITE)
- Uso de writeStream: Para escribir datos en modo streaming, se debe utilizar la función writeStream en lugar de write.
- Cambiar el atributo
mode(overwrite)por.outputMode(❓❓) - writeStream no soporta save()
- La salida será una carpeta, no un archivo.
- Hay que añadir un “trigger” que se dispare cada 5 minutos (para pruebas podemos poner 10 segundos)
.trigger(processingTime="5 minutes") - Finalizamos el writer con
.start() - Después del writer añadimos las siguientes líneas:
facturaWriterQuery.explain(True)facturaWriterQuery.awaitTermination()Ampliación
- Configuración de maxFilesPerTrigger: Esta opción limita el número de archivos que se procesan en cada micro-lote, permitiendo controlar la cantidad de datos ingeridos. Limitar a 1 archivo por vez.
- Archivado o eliminación de archivos procesados: Para gestionar los archivos una vez procesados, se pueden utilizar las opciones cleanSource y sourceArchiveDir.
- cleanSource: Define la acción a realizar con los archivos procesados. Puede tomar los valores archive (archivar) o delete (eliminar).
- sourceArchiveDir: Especifica el directorio donde se moverán los archivos si se elige la opción de archivado.
- Al writer le añadimos la opción:
.option("checkpointLocation", "chk-point-dir")¿Para qué sirve?
Es importante considerar que archivar o eliminar archivos procesados puede impactar en el rendimiento de los micro-lotes. Si los micro-lotes son largos, se puede utilizar la opción cleanSource. En caso de que los micro-lotes sean cortos y la demora introducida por cleanSource no sea aceptable, es recomendable implementar un proceso de limpieza separado que se ejecute periódicamente para gestionar el directorio de entrada. Al implementar estas modificaciones, el programa podrá procesar de manera continua los archivos de facturas que se añadan a la carpeta ENTRADA, transformarlos y guardarlos en la carpeta SALIDA, manteniendo la eficiencia y la tolerancia a fallos en el procesamiento de datos en tiempo real.
### AYUDAinvoice_schema = StructType([ StructField("InvoiceNumber", StringType(), True), StructField("CreatedTime", StringType(), True), StructField("StoreID", StringType(), True), StructField("PosID", StringType(), True), StructField("CustomerType", StringType(), True), StructField("PaymentMethod", StringType(), True), StructField("DeliveryType", StringType(), True), StructField("InvoiceLineItems", ArrayType(StructType([ StructField("ItemCode", StringType(), True), StructField("ItemDescription", StringType(), True), StructField("ItemPrice", DoubleType(), True), StructField("ItemQty", IntegerType(), True), StructField("TotalValue", DoubleType(), True) ])), True)])Código anterior
Section titled “Código anterior”from pyspark.sql import SparkSession
spark = SparkSession.builder.getOrCreate()raw_df = spark.read.json("./invoices/ENTRADA/*.json")
explode_df = raw_df.selectExpr("InvoiceNumber", "CreatedTime", "StoreID", "PosID", "CustomerType", "PaymentMethod", "DeliveryType", "explode(InvoiceLineItems) as LineItem")
from pyspark.sql.functions import exprlimpio_df = explode_df \ .withColumn("ItemCode", expr("LineItem.ItemCode")) \ .withColumn("ItemDescription", expr("LineItem.ItemDescription")) \ .withColumn("ItemPrice", expr("LineItem.ItemPrice")) \ .withColumn("ItemQty", expr("LineItem.ItemQty")) \ .withColumn("TotalValue", expr("LineItem.TotalValue")) \ .drop("LineItem")
facturaWriterQuery = limpio_df.write \ .format("json") \ .mode("overwrite") \ .option("path", "./invoices/salidatmp2.json") \ .save()Monitorización
Section titled “Monitorización”Una vez hemos realizado una consulta, podemos obtener información sobre la misma de forma programativa:
facturaWriterQuery.explain() # muestra una explicación detalla del plan de ejecución# == Physical Plan ==# *(1) Project [InvoiceNumber#314, CreatedTime#308L, StoreID#319, PosID#317, CustomerType#310, PaymentMethod#316, DeliveryType#312, _extract_City#339 AS City#52, _extract_State#340 AS State#53, _extract_PinCode#341 AS PinCode#54, LineItem#55.ItemCode AS ItemCode#67, LineItem#55.ItemDescription AS ItemDescription#81, LineItem#55.ItemPrice AS ItemPrice#96, LineItem#55.ItemQty AS ItemQty#112L, LineItem#55.TotalValue AS TotalValue#129]# ...facturaWriterQuery.recentProgress # muestra una lista de los últimos progresos de la consulta# [{'id': '3b6d37cf-6a3c-405e-a715-1dc787f34b00',# 'runId': '3dc7c478-626a-4558-87ea-4912da55114d',# 'name': 'Facturas Writer',# 'timestamp': '2024-05-11T08:20:49.058Z',# 'batchId': 0,# 'numInputRows': 500,# 'inputRowsPerSecond': 0.0,# 'processedRowsPerSecond': 113.55893708834887,# 'durationMs': {'addBatch': 2496,# ...facturaWriterQuery.lastProgress # muestra el último progreso# {'id': '3b6d37cf-6a3c-405e-a715-1dc787f34b00',# 'runId': '3dc7c478-626a-4558-87ea-4912da55114d',# 'name': 'Facturas Writer',# 'timestamp': '2024-05-11T08:33:00.001Z',# 'batchId': 3,# 'numInputRows': 0,# 'inputRowsPerSecond': 0.0,# 'processedRowsPerSecond': 0.0,# 'durationMs': {'latestOffset': 5, 'triggerExecution': 8},# ...Estas mismas estadísticas las podemos obtener de forma gráfica. Al ejecutar procesos en Streaming, si accedemos a Spark UI, ahora podremos ver la pestaña Structured Streaming con información detallada de la cantidad datos de entrada, tiempo procesado y duración de los micro-batches:
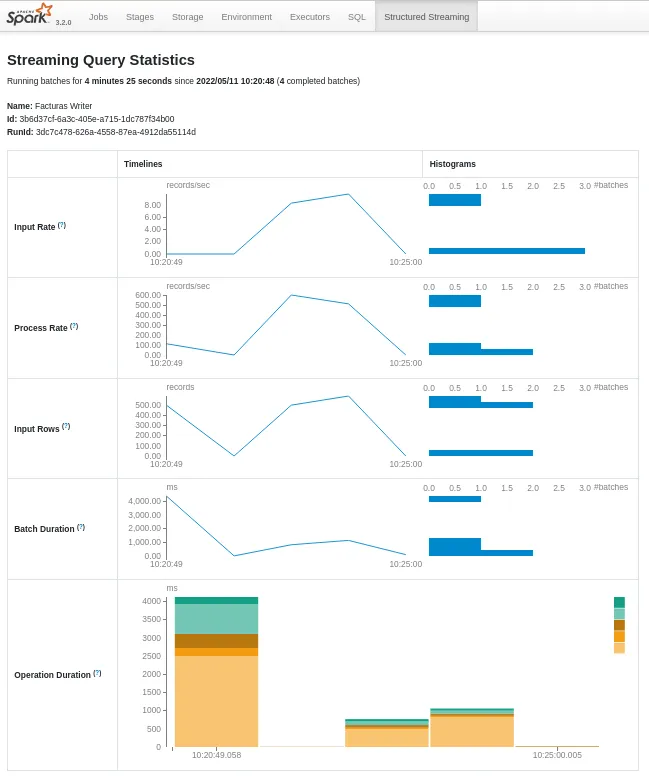
Además, podemos iniciar tantas consultas como queramos en una única sesión de Spark, las cuales se ejecutarán de forma concurrente utilizando los recursos del clúster de Spark.
[!INFO] Para acceder a la webUI deberíamos de mapear los puertos tal y como lo hicimos anteriormente docker run -it -p 8888:8888 -p 4040:4040 -p 4041:4041 -p 4042:4042 -v $(pwd):/home/jovyan/work/projects/ jupyter/pyspark-notebook
Tolerancia a fallos
Section titled “Tolerancia a fallos”Un aplicación en streaming se espera que se ejecute de forma ininterrumpida mediante un bucle infinito de micro-batches.
Realmente, un escenario de ejecución infinita no es posible, ya que la aplicación se detendrá por:
- un fallo, ya sea por un dato mal formado o un error de red.
- mantenimiento del sistema, para actualizar la aplicación o el hardware donde corre.
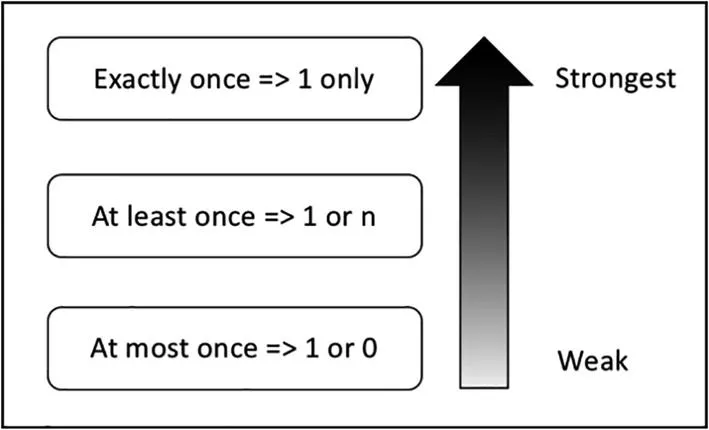
Para tratar la tolerancia a fallos, existen tres escenarios posibles:
- Una vez como mucho (at most once): no se entrega más de una copia de un dato. Es decir, puede darse el caso de que no llegue, pero no habrá repetidos.
- Una vez al menos (at least once): en este caso no habrá pérdidas, pero un dato puede llegar más de una vez.
- Una vez exacta (exactly once): se garantiza que cada dato se entrega una única vez, sin pérdidas ni duplicados.
Por ello, una aplicación Spark Streaming se debe reiniciar de forma transparente para mantener la característica de exactly-once la cual implica que:
- No se pierde ningún registro
- No crea registros duplicados.
Para ello, Spark Structured Streaming mantiene el estado de los micro-batches mediante checkpoints que se almacenan en la carpeta indicada por la opción checkpointLocation:
facturaWriterQuery = limpio_df.writeStream \ .format("json") \ .queryName("Facturas Writer") \ .outputMode("append") \ .option("path", "salida") \ .option("checkpointLocation", "chk-point-dir") \ .trigger(processingTime="1 minute") \ .start()La localización de esta carpeta debería ser un sistema de archivo confiable y tolerante a fallos, como HDFS o Amazon S3.
Esta carpeta contiene dos elementos:
- Posición de lectura, que realiza la misma función que los offset en Kafka, y representa el inicio y el final del rango de datos procesados por el actual micro-batch, de manera que Spark conoce el progreso exacto del procesamiento. Una vez ha finalizado el micro-batch, Spark realiza un commit para indicar que se han procesado los datos de forma exitosa.
- Información del estado, que contiene los datos intermedios del micro-batch, como la cantidad total de palabras contadas.
De esta manera, Spark mantiene toda la información necesaria para reiniciar un micro-batch que no ha finalizado. Sin embargo, la capacidad de reiniciarse no tiene por qué garantizar la política exactly-once. Para ello, es necesario cumplir los siguientes requisitos:
- Reiniciar la aplicación con el mismo
checkpointLocation. Si se elimina la carpeta o se ejecuta la misma consulta sobre otro directorio de checkpoint es como si realizásemos una consulta desde 0. - Utilizar una fuente de datos que permita volver a leer los datos incompletos del micro-batch, por ejemplo, tanto los ficheros de texto como Kafka permiten volver a leer los datos desde un punto determinado. Sin embargo, los datos que provienen de un socket no permite volver a leerlos.
- Asegurar que la lógica de aplicación, dados los mismos datos de entrada, produce siempre el mismo resultado (aplicación determinista). Si por ejemplo, nuestra lógica de aplicación utilizará alguna dependencia basada en fechas o el tiempo, ya no obtendríamos el mismo resultado.
- El destino (sink) debe ser capaz de identificar los elementos duplicados e ignorarlos o actualizar la copia antigua con el mismo registro, es decir, son idempotentes.