Kafka
Introducción y Objetivos
Section titled “Introducción y Objetivos”Imagina que tienes una aplicación de comercio electrónico diseñada con microservicios. En un modelo tradicional (comunicación síncrona, tipo API REST), si el servicio de pagos necesita notificar al servicio de envíos, ambos deben estar encendidos y responder al instante. ¿Qué pasa si el servicio de envíos se cae o si hay un pico repentino de miles de compras? El sistema podría colapsar o perder peticiones.
Aquí es donde entra en juego la comunicación asíncrona y las plataformas de transmisión de eventos como Apache Kafka. En lugar de hablar directamente entre ellos, los servicios “publican” los eventos (ej. “pago realizado”) en un flujo continuo temporal, y otros servicios se “suscriben” para leerlos a su propio ritmo.
En este documento aprenderás a:
- Diferenciar el procesamiento Batch (lotes) del procesamiento en Tiempo Real (streaming).
- Entender la arquitectura base de Kafka: Topics, Brokers, Producers y Consumers.
- Desplegar un clúster local monolítico de Kafka usando contenedores Docker.
- Escribir productores y consumidores básicos usando Python y Node.js.
Procesamiento de datos
Section titled “Procesamiento de datos”Procesamiento en lote (Batch Processing):
- Se envía un trabajo (por ejemplo, MapReduce, Spark o Hive) usando Yarn.
- El sistema ejecuta el trabajo y devuelve una respuesta en pantalla o escribe la salida en HDFS.
- Se ejecuta en intervalos regulares (cada hora, cada día, etc.).
- Es ideal para comenzar con Big Data, pero no es adecuado cuando se requiere procesar datos en intervalos muy cortos.
Procesamiento en tiempo real (Real-Time Processing):
- Se utiliza cuando hay necesidad de procesar los datos casi inmediatamente después de que llegan.
- Requiere tecnologías y arquitecturas específicas para manejar flujos constantes de datos.
Procesamiento en Tiempo Real
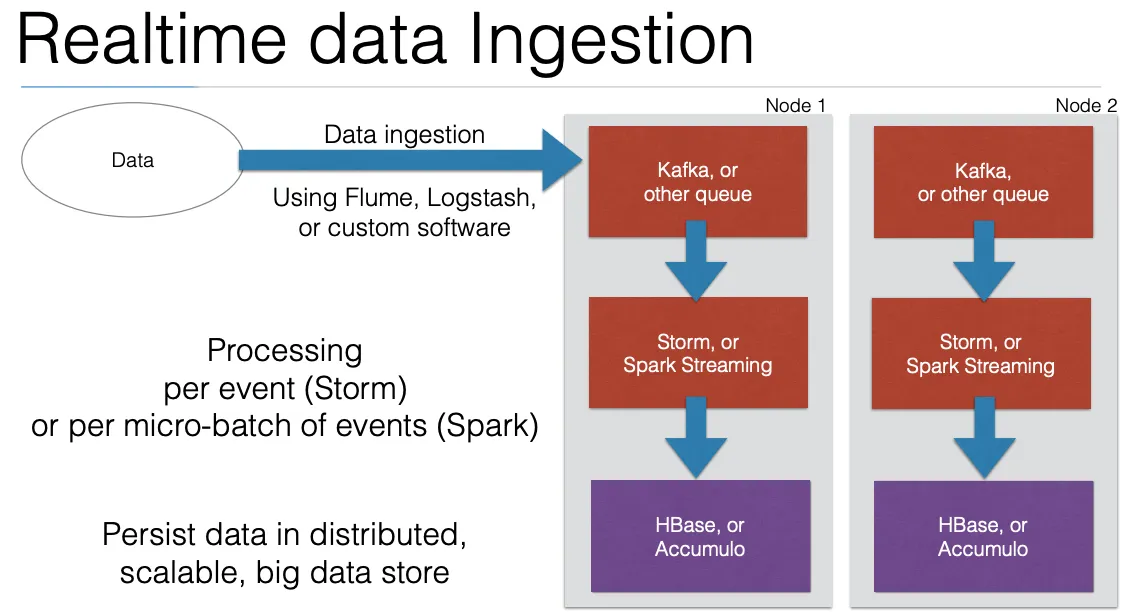
Section titled “Procesamiento en Tiempo Real”Ingesta y almacenamiento temporal de datos: Los datos entrantes deben almacenarse temporalmente antes de ser procesados.
Problema con HDFS:
- HDFS no es eficiente para leer eventos individuales (como una línea o un registro).
- Está diseñado para leer bloques completos de datos.
SOLUCIÓN Kafka:
- Kafka es un sistema de mensajería basado en el modelo publicación-suscripción (pub-sub).
- Actúa como un log distribuido que almacena eventos temporalmente en un buffer mientras esperan para ser procesados.
Procesamiento de Eventos en Tiempo Real
Section titled “Procesamiento de Eventos en Tiempo Real”Los servicios que procesan los datos deben estar en ejecución continua dentro del clúster de Hadoop y deben recuperar datos desde sistemas de colas como Kafka. Diferentes enfoques para el procesamiento de eventos:
- Storm: Procesa cada evento de manera individual.
- Storm + Trident: Permite agrupar eventos (batching) y procesar múltiples eventos a la vez.
- Spark Streaming: Utiliza un enfoque de micro-lotes (micro-batching), agrupando eventos dentro de intervalos de tiempo cortos (por ejemplo, cada pocos segundos).
Almacenamiento Persistente de Datos Procesados
Section titled “Almacenamiento Persistente de Datos Procesados”Después de procesar los datos, deben almacenarse para consultas posteriores.
Problema con HDFS:
- No es adecuado para manejar muchos archivos pequeños.
- Una posible solución sería anexar eventos a un único archivo grande, pero esto hace que la lectura de un evento específico sea difícil.
Soluciones ideales:
- Utilizar almacenes de datos distribuidos como:
- HBase: Diseñado para escritura rápida y lectura eficiente cuando se conoce la clave de fila.
- Accumulo: Similar a HBase, pero con funcionalidades adicionales como control de acceso granular.
https://aitor-medrano.github.io/iabd/dataflow/kafka1.html
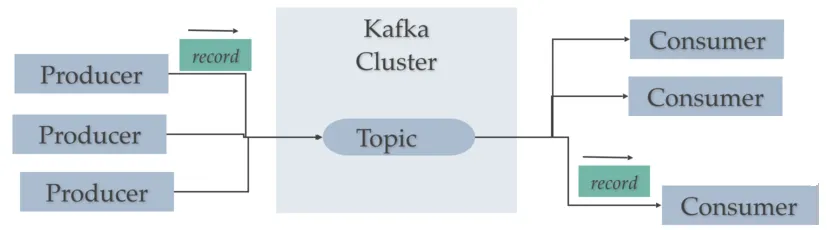
Apache Kafka es, en pocas palabras, un middleware de mensajería entre sistemas heterogéneos, el cual, mediante un sistema de colas (topics, para ser concreto) facilita la comunicación asíncrona, desacoplando los flujos de datos de los sistemas que los producen o consumen. Funciona como un broker de mensajes, encargado de enrutar los mensajes entre los clientes de un modo muy rápido.
Supongamos que tenemos múltiples generadores de datos, ya sean servidores web, de bases de datos, un servidor de chat y que todos ellos tienen que almacenar sus datos en múltiples destinos, como pueden ser logs, métricas de rendimiento y monitorización, el carrito de la compra o los fallos ocurridos, lo que puede provocar una serie de dependencias de unos con otros. Para evitarlo, Kafka viene al rescate conectando todos los generadores de datos (productores) a Kafka y a su vez, a todos los consumidores de estos datos.
En concreto, se trata de una plataforma open source distribuida de transmisión de eventos/mensajes en tiempo real con almacenamiento duradero y que proporciona de base un alto rendimiento (capaz de manejar billones de peticiones al día, con una latencia inferior a 10ms), tolerancia a fallos, disponibilidad y escalabilidad horizontal (mediante cientos de nodos).
Más del 80% de las 100 compañías más importantes de EEUU utilizan Kafka: Uber, Twitter, Netflix, Spotify, Blizzard, LinkedIn, Spotify, y PayPal procesan cada día sus mensajes con Kafka.
https://kafka.apache.org/powered-by
Como sistema de mensajes, sigue un modelo publicador-suscriptor. Su arquitectura tiene dos directivas claras:
- No bloquear los productores (para poder gestionar la back pressure, la cual sucede cuando un publicador produce más elementos de los que un suscriptor puede consumir).
- Aislar los productores y los consumidores, de manera que los productores y los consumidores no se conocen.
A día de hoy, Apache Kafka se utiliza, además de como un sistema de mensajería, para ingestar datos, realizar procesado de datos en streaming y analítica de datos en tiempo real, así como en arquitectura de microservicios y sistemas IOT.
Publicador / Suscriptor (Productor / consumidor)
Section titled “Publicador / Suscriptor (Productor / consumidor)”Antes de entrar en detalle sobre Kafka, hay que conocer el modelo publicador/suscriptor. Este patrón también se conoce como publish / subscribe o productor / consumidor.
Hay tres elementos que hay que tener realmente claros:
- Publicador (publisher / productor / emisor): genera un dato y lo coloca en un topic como un mensaje.
- Topic (tema): almacén temporal/duradero que guarda los mensajes funcionando como una cola.
- Suscriptor (subscriber / consumidor / receptor): recibe el mensaje.
Cabe destacar que un productor no se comunica nunca directamente con un consumidor, siempre lo hace a través de un topic:
 https://www.youtube.com/watch?v=wO6DCLU4uxE
https://www.youtube.com/watch?v=wO6DCLU4uxE
Arquitectura Interna
Section titled “Arquitectura Interna”Para entender por qué Kafka es capaz de procesar millones de mensajes por segundo sin perder datos, debemos conocer cómo almacena la información por debajo:
- Particiones (Partitions): Un Topic no es una sola lista o archivo, se divide en múltiples “particiones” repartidas entre varios Brokers. Esto permite que varios productores y consumidores escriban y lean datos en paralelo. La partición es la unidad fundamental de escalabilidad.
- El Commit Log Inmutable: A diferencia de RabbitMQ (donde el mensaje se borra tras ser leído), Kafka guarda los mensajes en disco de forma secuencial y solo añade al final (Append-only). Los mensajes no se borran y el archivo es inmutable.
- Offsets: Cada mensaje dentro de una partición recibe un número secuencial único llamado Offset. Los consumidores utilizan este número para saber “por dónde van leyendo”. Si un consumidor se apaga, cuando vuelve a encenderse busca su último offset guardado y continúa desde ahí.
- Claves (Keys) y Orden: Kafka solo garantiza el orden de los mensajes si están en la misma partición. Para asegurarnos de que, por ejemplo, todos los eventos del “sensor-1” se procesan en el orden correcto, el Productor debe adjuntar la clave
sensor-1al mensaje. Kafka calculará un hash de esa clave y siempre enviará los mensajes con esa clave a la misma partición.
Escalabilidad con Consumer Groups
Section titled “Escalabilidad con Consumer Groups”Si tenemos un Topic produciendo 10.000 mensajes por segundo, un solo script en Python (Consumidor) no podrá leerlos a tiempo. La solución de Kafka son los Grupos de Consumidores (Consumer Groups).
- Varios consumidores se unen bajo el mismo nombre de grupo (ej.
grupo-procesamiento-pagos). - Kafka reparte automáticamente las particiones del Topic entre los miembros del grupo.
- Regla de oro: Una partición solo puede ser leída por un consumidor dentro de un mismo grupo. (Si tienes 5 particiones, no sirve de nada tener 6 consumidores en ese grupo, uno se quedará ocioso).
Retención y Tolerancia a Fallos
Section titled “Retención y Tolerancia a Fallos”Como Kafka guarda los datos en disco y no los borra al leerlos, ¿qué impide que el disco se llene?
- Políticas de Retención: Se configura Kafka para borrar mensajes antiguos por tiempo (ej. retener datos 7 días) o por tamaño (ej. máximo 100GB por partición).
- Factor de Replicación: Para que no se pierdan datos si un servidor físico (Broker) se quema o se apaga, Kafka replica las particiones. Con un
Replication_Factor=3, los datos se guardan en 3 servidores distintos. Si se cae uno, el clúster sigue funcionando sin enterarse.
Instalación Kafka
Section titled “Instalación Kafka”En local
Section titled “En local”https://kafka.apache.org/quickstart
Contenedores
Section titled “Contenedores”En este curso utilizaremos la arquitectura moderna KRaft (Kafka Raft), que elimina la necesidad de contenedores adicionales (como Zookeeper) para gestionar el clúster.
Para instalar la versión, debemos entrar a nuestro “laboratorio” BigDataAplicadoLab y hacer:
git pull
cd modulo02kafka
docker-compose up -dEl archivo docker-compose.yml tiene la siguiente configuración:
services: kafka-broker-1: image: confluentinc/cp-kafka:latest container_name: kafka-broker-1 environment: KAFKA_KRAFT_MODE: "true" KAFKA_PROCESS_ROLES: "broker,controller" KAFKA_NODE_ID: 1 CLUSTER_ID: "q1Sh-9_ISia_zwGINzRvyQ"
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: "PLAINTEXT:PLAINTEXT,CONTROLLER:PLAINTEXT" KAFKA_LISTENERS: "PLAINTEXT://0.0.0.0:9092,CONTROLLER://0.0.0.0:9093" KAFKA_ADVERTISED_LISTENERS: "PLAINTEXT://localhost:9092" KAFKA_CONTROLLER_LISTENER_NAMES: "CONTROLLER" KAFKA_CONTROLLER_QUORUM_VOTERS: "1@kafka-broker-1:9093"
KAFKA_LOG_DIRS: "/var/lib/kafka/data" KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: 1 KAFKA_TRANSACTION_STATE_LOG_MIN_ISR: 1 KAFKA_TRANSACTION_STATE_LOG_REPLICATION_FACTOR: 1 ports: - "9092:9092" volumes: - kafka-data:/var/lib/kafka/data
volumes: kafka-data:Abrimos 2 terminales:
# Terminal 1docker exec -it kafka-broker-1 bash# Terminal 2docker exec -it kafka-broker-1 bash
# Terminal 1, creamos topic test1$ kafka-topics --bootstrap-server kafka-broker-1:9092 --create --topic test1## (productor) Escribimos mensajes dentros de este topic$ kafka-console-producer --bootstrap-server kafka-broker-1:9092 --topic test1> hola> uno> dos> tres
# Terminal 2, creamos consumidor## (consumidor)kafka-console-consumer --bootstrap-server kafka-broker-1:9092 --topic test1 --from-beginningAbrimos otro terminal
docker exec -it kafka-broker-1 bash
# Creamos nuevo topic$ kafka-topics --bootstrap-server kafka-broker-1:9092 --create --topic test2
# Listamos los topics disponibles$ kafka-topics --list --bootstrap-server kafka-broker-1:9092
# Mandamos mensajes al topic "test2"kafka-console-producer --bootstrap-server kafka-broker-1:9092 --topic test2
# No se muestran por la terminal2, ya que se encuentra escuchando# otra "categoría"Ejemplos
Section titled “Ejemplos”Posibles ERRORES se solucionan con la versión *-ng :
pip install kafka-python-ngProducer desde python
Section titled “Producer desde python”'''pip install kafka-python'''
from kafka import KafkaProducerimport time
# Configuración del servidor Kafka y el tema al que enviaremos mensajesbootstrap_servers = ['127.0.0.1:9092']topic_name = 'test1'
# Crear un productor de Kafkaproducer = KafkaProducer(bootstrap_servers=bootstrap_servers)
# Enviar mensajes al temafor i in range(1, 6): mensaje = f"Mensaje {i}" producer.send(topic_name, mensaje.encode('utf-8')) print(f"Mensaje enviado: {mensaje}") time.sleep(1) # Esperar 1 segundo entre cada mensaje
producer.close()Consumer desde python
Section titled “Consumer desde python”'''pip install kafka-python'''
from kafka import KafkaConsumer
# Configuración del servidor Kafka y el tema al que nos conectaremosbootstrap_servers = ['localhost:9092']topic_name = 'mi_tema'
# Crear un consumidor de Kafka y configurarlo para leer desde el inicio del temaconsumer = KafkaConsumer(topic_name, group_id='grupo1', bootstrap_servers=bootstrap_servers, auto_offset_reset='earliest')
# Leer mensajes del tema desde el iniciofor mensaje in consumer: print(f"Mensaje recibido: {mensaje.value.decode('utf-8')}")Producer - Consumer desde node
Section titled “Producer - Consumer desde node”npm init
npm install kafka-nodeconst kafka = require('kafka-node');
const client = new kafka.KafkaClient({kafkaHost: '127.0.0.1:9092'})
/* Consumer */var consumer = new kafka.Consumer(client, [{topic:'test1'}])consumer.on('message', function(message) { console.log(message)});
/* Producer */var producer = new kafka.Producer(client);producer.on('ready', function () { setInterval(function() { producer.send( [ { topic: "test1", messages: "Mensaje automático cada 5 seg." } ], function (err,data) {} ); }, 5000);});node index.js
{ topic: 'test1', value: 'hola', offset: 0, partition: 0, highWaterOffset: 7, key: null}{ topic: 'test1', value: 'uno dos', offset: 1, partition: 0, highWaterOffset: 7, key: null}Práctica Guiada: Escalabilidad con Consumer Groups
Section titled “Práctica Guiada: Escalabilidad con Consumer Groups”Vamos a comprobar cómo Kafka reparte el trabajo (escalabilidad horizontal) simulando un sistema de votaciones en tiempo real para un concurso de talentos (tipo Operación Triunfo o Eurovisión). Miles de votos llegan por segundo, y un solo consumidor no daría abasto.
Usaremos Particiones, Claves (Keys) y Consumer Groups.
Paso 1: Crear un Topic con múltiples particiones
Section titled “Paso 1: Crear un Topic con múltiples particiones”Si te equivocas creando un Topic o quieres borrar todos sus mensajes retenidos, puedes eliminarlo con:
kafka-topics --bootstrap-server kafka-broker-1:9092 --delete --topic votos-eurovision
Hasta ahora nuestros topics tenían 1 sola partición. Vamos a crear el topic votos-eurovision con 3 particiones.
docker exec -it kafka-broker-1 bash
kafka-topics --bootstrap-server kafka-broker-1:9092 --create --topic votos-eurovision --partitions 3Paso 2: El Productor (Enviando votos con Clave)
Section titled “Paso 2: El Productor (Enviando votos con Clave)”Vamos a simular la App Móvil. Emitirá votos aleatorios, pero usará el DNI/Teléfono del usuario como Key. ¿Por qué? Porque queremos garantizar que todos los votos de la misma persona vayan a la misma partición y se procesen en orden estricto, para evitar dobles conteos o fraudes.
Crea el archivo productor_votos.py (recuerda tener instalado kafka-python-ng):
from kafka import KafkaProducerimport jsonimport timeimport random
# Configuración: indicamos que enviaremos JSONs y las Keys serán stringsproducer = KafkaProducer( bootstrap_servers=['localhost:9092'], value_serializer=lambda v: json.dumps(v).encode('utf-8'), key_serializer=lambda k: k.encode('utf-8'))
candidatos = ["Alice", "Bob", "Charlie", "Diana"]
print("📱 App de Votación iniciada. Enviando votos...")
for i in range(1, 1000): # Simulamos 5 usuarios votando (IDs del 1 al 5) id_usuario = f"usuario-{random.randint(1, 5)}"
mensaje = { "id_voto": i, # Añadimos un contador secuencial "candidato": random.choice(candidatos), "origen": "App iOS" }
# La KEY (id_usuario) es vital. Kafka hará un hash y lo enviará siempre a la misma partición. producer.send('votos-eurovision', key=id_usuario, value=mensaje) print(f"Enviado {id_usuario}: {mensaje}") time.sleep(1)
producer.close()Paso 3: Los Consumidores (El Escrutinio)
Section titled “Paso 3: Los Consumidores (El Escrutinio)”Ahora vamos a levantar el centro de cálculo de votos. Crea consumidor_votos.py:
from kafka import KafkaConsumerimport json
# Unimos este consumidor al grupo "grupo-escrutinio"consumer = KafkaConsumer( 'votos-eurovision', bootstrap_servers=['localhost:9092'], group_id='grupo-escrutinio', # IMPORTANTE auto_offset_reset='earliest', value_deserializer=lambda m: json.loads(m.decode('utf-8')), key_deserializer=lambda k: k.decode('utf-8') if k else None)
print("📊 Centro de Escrutinio iniciado. Esperando votos...")
for mensaje in consumer: id_voto = mensaje.value["id_voto"] candidato = mensaje.value["candidato"] print(f"Recibido Voto #{id_voto} en [Partición {mensaje.partition}] - Key: {mensaje.key} -> {candidato}")Paso 4: El Experimento Final (Rebalanceo)
Section titled “Paso 4: El Experimento Final (Rebalanceo)”- Abre 3 terminales distintas.
- En cada una de ellas, ejecuta el consumidor:
python consumidor_votos.py. Las tres se quedarán “escuchando”. - Abre una cuarta terminal y ejecuta el app móvil:
python productor_votos.py.
Observa lo que ocurre:
- Los votos se están repartiendo entre las 3 terminales y cada terminal procesa una partición distinta (verás que la Terminal 1 solo procesa la
Partición 0, la Dos laPartición 1, etc.). - Fíjate que el
usuario-2SIEMPRE cae en la misma terminal. La clave funcionó.
Simulacro de Caída:
Mientras el productor sigue enviando votos, ve a una de las terminales del consumidor y ciérrala repentinamente (Ctrl+C) simulando que se quemó el servidor.
Observa las otras 2 terminales y fíjate en los números de los id_voto. Verás que una de las terminales “absorbe” la partición del nodo caído tras un pequeño parón y sigue procesando. ¡No se pierde ningún número de voto en la secuencia! A este salto automático y tolerancia a fallos se le llama Rebalanceo de Kafka.
Actividades
Section titled “Actividades”✅ Entregar AULES
Actividad 1: Enriquecimiento de Datos en Vuelo
Section titled “Actividad 1: Enriquecimiento de Datos en Vuelo”En el mundo real, los sensores IoT envían el mínimo dato posible para ahorrar ancho de banda. La información adicional (zona, responsable, etc.) vive en otro sistema. Tu trabajo como ingeniero/a de datos es unirlo todo antes de persistirlo.
Escenario: Tienes un invernadero con 4 sensores (S-01 a S-04). Cada sensor solo envía su ID y la temperatura bruta. Tú dispones de una tabla de metadatos de cada sensor.
Crea 2 scripts Python:
-
productor_iot.py— Emite un mensaje al topictelemetria-iotcada 2 segundos. El JSON solo debe contener:sensor_id(aleatorio entre S-01 y S-04)temperatura(valor float aleatorio entre 15 y 38ºC)
-
consumidor_iot.py— Lee del topic, enriquece el mensaje y lo guarda en MongoDB. El documento final en la coleccióntelemetria_enriquecidadebe incluir además:ubicacion(ej. “Invernadero Norte”)responsable(ej. “Ana”)timestamp(momento de recepción del mensaje)
Datos de los sensores:
| sensor_id | ubicacion | responsable |
|---|---|---|
| S-01 | Invernadero Norte | Ana |
| S-02 | Invernadero Sur | Pedro |
| S-03 | Almacén Semillas | Laura |
| S-04 | Zona de Cuarentena | Marc |
Ejemplo del documento esperado en MongoDB:
{ "sensor_id": "S-02", "temperatura": 33.4, "ubicacion": "Invernadero Sur", "responsable": "Pedro", "timestamp": "2026-03-09T13:00:00"}Entrega: Los 2 scripts .py y una captura de la colección MongoDB con al menos 10 documentos.
Actividad 2: Pipeline de Dos Topics
Section titled “Actividad 2: Pipeline de Dos Topics”En arquitecturas reales, los microservicios están desacoplados: quien detecta el problema no es quien actúa ni quien guarda. Esta actividad simula esa arquitectura.
Escenario: Una red de sensores envía telemetría continuamente. Solo los datos críticos (temperatura > 30ºC) deben llegar a MongoDB. El pipeline tiene 3 componentes independientes:
[productor_sensor.py] ↓ topic: telemetria-bruta[filtro_alertas.py] ← consume y produce ↓ topic: alertas-criticas (solo temp > 30ºC)[consumidor_mongodb.py] ↓MongoDB: alertas_temperaturaCrea 3 scripts Python:
-
productor_sensor.py— Envía al topictelemetria-brutaun JSON consensor_id,temperatura(15-38ºC aleatorio) ytimestampcada segundo. -
filtro_alertas.py— Es a la vez consumidor y productor:- Lee mensajes de
telemetria-bruta. - Si
temperatura > 30, re-publica el mensaje en el topicalertas-criticas. - Si no supera el umbral, lo descarta sin guardarlo.
- Lee mensajes de
-
consumidor_mongodb.py— Lee exclusivamente del topicalertas-criticase inserta cada mensaje en MongoDB en la colecciónalertas_temperatura.
Entrega: Los 3 scripts .py y una captura mostrando que MongoDB solo contiene registros con temperatura > 30ºC.
Actividad 3: Análisis con Spark Structured Streaming
Section titled “Actividad 3: Análisis con Spark Structured Streaming”Hasta ahora has construido el pipeline de ingestión y filtrado con Python. Ahora la tarea es conectar Apache Spark Structured Streaming al topic alertas-criticas para hacer análisis agregado en tiempo real.
Pipeline completo:
[productor_sensor.py] → telemetria-bruta → [filtro_alertas.py] ↓ topic: alertas-criticas ↓ [PySpark Structured Streaming] ├── Script A: count por sensor └── Script B: avg(temp) por ventanaCrea 2 scripts PySpark:
-
spark_conteo.py— Conecta al topicalertas-criticasy calcula en tiempo real cuántas alertas ha generado cada sensor. El resultado debe imprimirse en consola en formato tabla cada 5 segundos.Salida esperada:
+---------+-----+|sensor_id|count|+---------+-----+| S-03| 7|| S-01| 4|| S-02| 12|+---------+-----+ -
spark_ventana.py— Conecta al mismo topic y calcula la temperatura media por sensor aplicando una ventana deslizante de 30 segundos que se actualiza cada 10 segundos. Usa eltimestampdel mensaje como tiempo del evento.Salida esperada:
+------------------------------------------+---------+----------+|window |sensor_id|temp_media|+------------------------------------------+---------+----------+|{2026-03-09 13:00:00, 2026-03-09 13:00:30}| S-02| 33.45||{2026-03-09 13:00:10, 2026-03-09 13:00:40}| S-04| 35.80|+------------------------------------------+---------+----------+
Entrega: Los 2 scripts .py y una captura de consola mostrando la tabla actualizada de cada uno.
Anexo: Arquitectura clásica (Zookeeper vs KRaft)
Section titled “Anexo: Arquitectura clásica (Zookeeper vs KRaft)”Zookeeper es un servicio de coordinación centralizada. Antiguamente, era obligatorio para:
- Mantenimiento del inventario de nodos activos (Brokers).
- Coordinación en la elección del broker líder para cada partición.
- Notificaciones de estado en tiempo real (creación/borrado de topics, caída de brokers).
A partir de Kafka 3.3, el modo KRaft (Kafka Raft) se convirtió en el estándar. KRaft integra la gestión de metadatos dentro del propio Kafka, lo que:
- Permite escalar a millones de particiones.
- Simplifica el despliegue (menos contenedores que mantener).
- Elimina cuellos de botella de rendimiento que existían al comunicarse con Zookeeper.