Monitorización con Prometheus
![]()
Imagina que eres el director de una gran fábrica (tu infraestructura Big Data). Para que todo funcione, necesitas saber qué está pasando en cada rincón: ¿cuántas piezas se fabrican por segundo? ¿hay alguna máquina sobrecalentada? ¿cuántos obreros están libres?
Prometheus es tu Inspector Jefe. No espera a que las máquinas le envíen informes; él mismo recorre la fábrica con su libreta (base de datos de series temporales), visita cada departamento y anota los números actuales. En este tema aprenderás a configurar a este inspector para que no se le escape ningún detalle de tu clúster.
1. Arquitectura: ¿Cómo funciona el “Inspector”?
Section titled “1. Arquitectura: ¿Cómo funciona el “Inspector”?”A diferencia de otros sistemas que “reciben” datos, Prometheus utiliza un modelo Pull. Él es quien toma la iniciativa de pedir la información.
El flujo de datos
Section titled “El flujo de datos”graph LR subgraph "Exporters (Los Departamentos)" NE["Node Exporter<br/>(El Host: CPU/RAM)"] CA["cAdvisor<br/>(Contenedores Docker)"] NX["Nginx Exporter<br/>(Tráfico Web)"] end
subgraph "Core (El Inspector Jefe)" P["<b>Prometheus</b><br/>(Scraping & Storage)"] end
subgraph "Visualización (El Panel de Control)" G["Grafana"] end
NE -- "Exponen métricas en port:9100" --> P CA -- "Exponen métricas en port:8080" --> P NX -- "Exponen métricas en port:9113" --> P
P -- "Pull (Scrape) cada 15s" --> NE P -- "Pull (Scrape) cada 15s" --> CA P -- "Pull (Scrape) cada 15s" --> NX
G -- "Consulta datos vía PromQL" --> P
style P fill:#e3f2fd,stroke:#1976d2,stroke-width:2px style G fill:#c8e6c9,stroke:#388e3c,stroke-width:2px style NE fill:#fff9c4,stroke:#f57c00 style CA fill:#fff9c4,stroke:#f57c00 style NX fill:#fff9c4,stroke:#f57c00Acceso a las Herramientas
Section titled “Acceso a las Herramientas”Aquí tienes los enlaces para interactuar con el inspector y sus departamentos:
| Herramienta | URL | Usuario / Pass | Función |
|---|---|---|---|
| Prometheus | http://localhost:9090 | - | Dashboard de consultas y estado. |
| Grafana | http://localhost:3000 | admin / admin | Visualización en paneles avanzados. |
| cAdvisor | http://localhost:8080 | - | Explorador visual de contenedores. |
| Node Exporter | http://localhost:9100/metrics | - | Datos brutos del Sistema Operativo. |
- Exporters: Son pequeños agentes que “traducen” las tripas del sistema (Linux, Docker, bases de datos) al idioma que entiende Prometheus.
- Scraping: Prometheus visita los endpoints
/metricsde cada exporter periódicamente. - TSDB (Time Series Database): Guarda los datos optimizando el espacio, asociando cada valor a una marca de tiempo.
2. Métricas
Section titled “2. Métricas”Ejemplo de métricas a las que accede prometheus nombre_etiqueta{LABELS}

Tipos de métricas: ¿Qué estamos midiendo?
Section titled “Tipos de métricas: ¿Qué estamos midiendo?”Prometheus clasifica la realidad en cuatro tipos. Saber distinguirlos es vital para elegir la función de consulta adecuada.
Counter (Contador)
Section titled “Counter (Contador)”Es un valor que solo aumenta. Piensa en el cuentakilómetros de un coche o el número de peticiones totales que ha recibido un servidor.
- ✅ Uso correcto:
http_requests_total,node_network_receive_bytes_total. - ❌ Uso incorrecto: La temperatura actual (porque puede bajar).
Con los contadores, casi siempre usaremos la función
rate()para ver la “velocidad” (ej: peticiones por segundo).
Escribe la consulta a continuación en la barra de consultas y haga clic en ejecutar. go_gc_duration_seconds_count
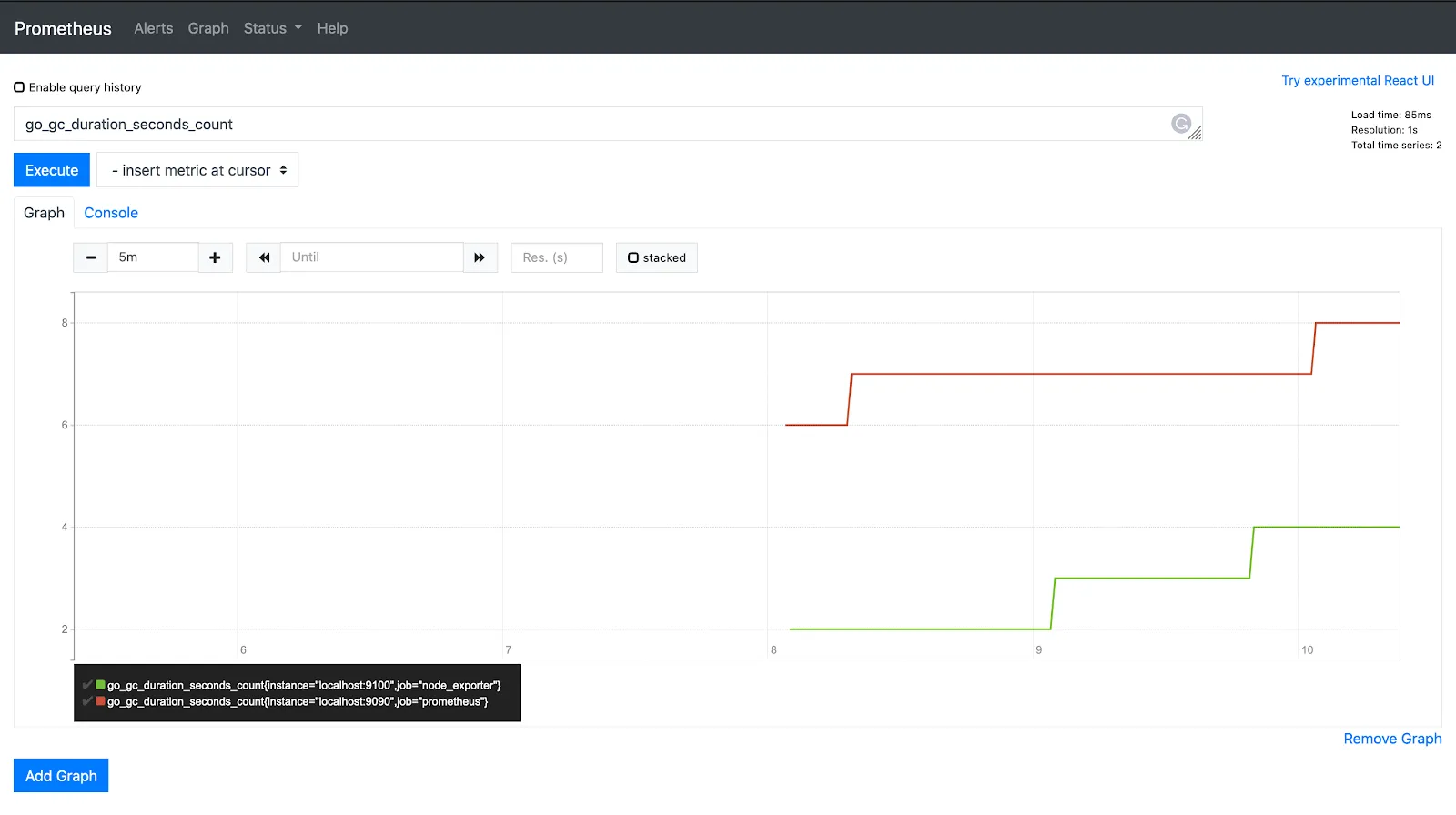
La función rate() en PromQL toma el historial de métricas durante un período de tiempo y calcula qué tan rápido aumenta el valor por segundo. La tasa es aplicable solo en valores de contador.
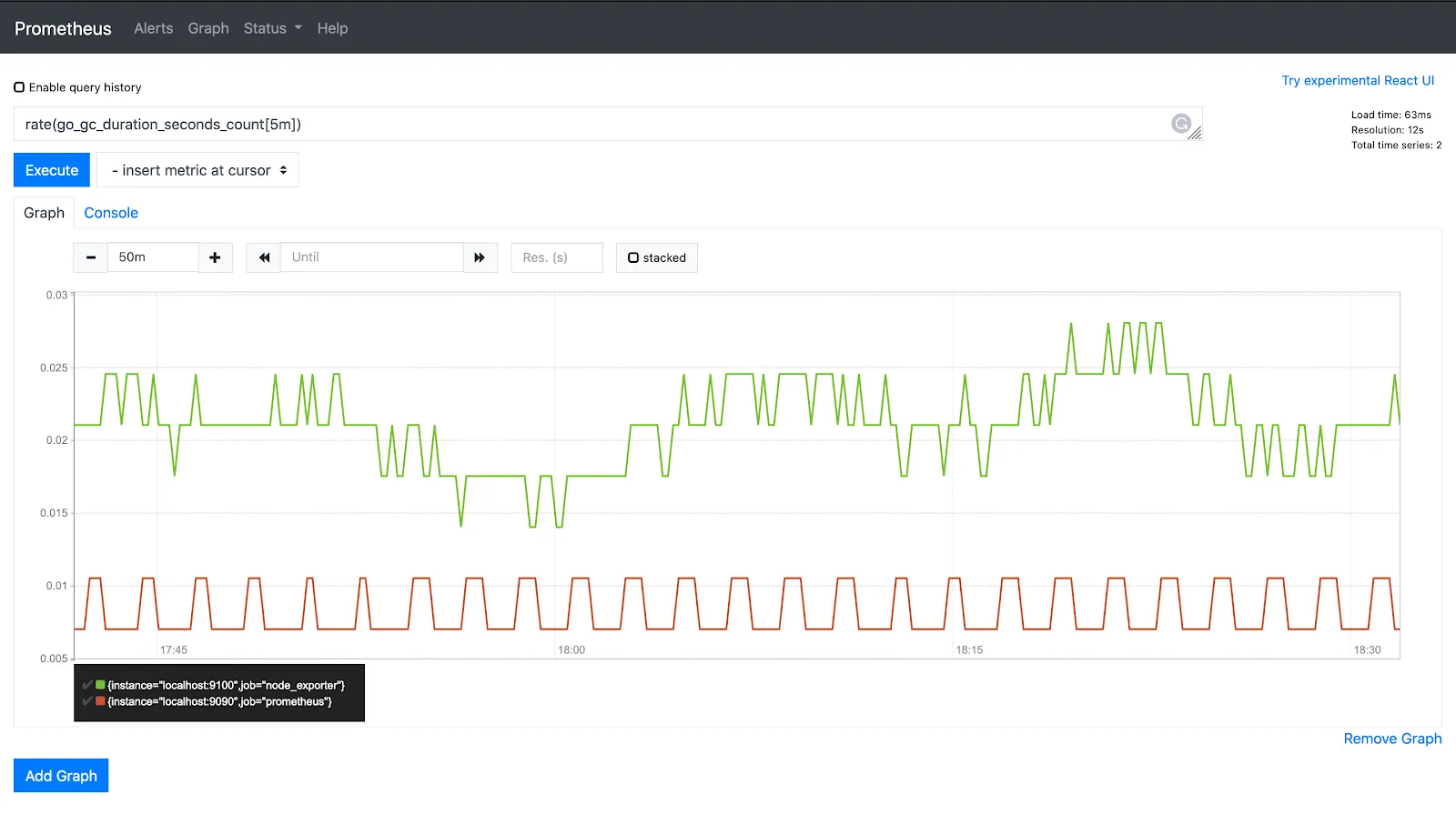
rate(go_gc_duration_seconds_count[5m])
Gauge (Indicador)
Section titled “Gauge (Indicador)”Un valor que sube y baja. Como el nivel de gasolina, la temperatura o el uso de memoria RAM.
- ✅ Uso correcto:
node_memory_MemAvailable_bytes,container_memory_usage_bytes. - ❌ Uso incorrecto: El número total de errores desde que se inició el sistema.
go_memstats_heap_alloc_bytes
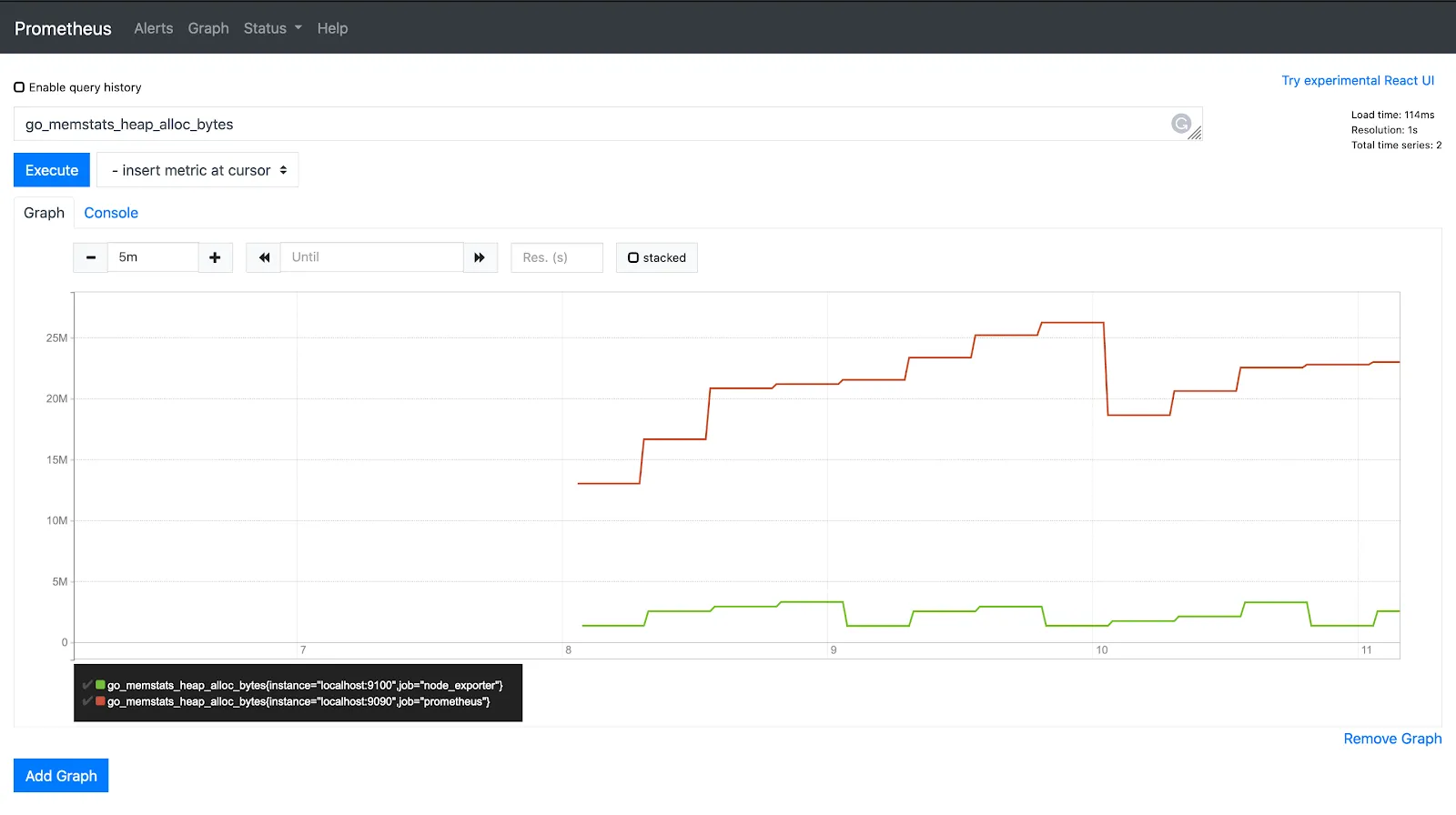
Funciones promQL como max_over_time, min_over_time y avg_over_time se puede utilizar en métricas de gauge.
Histogram (Histograma) y Summary (Resumen)
Section titled “Histogram (Histograma) y Summary (Resumen)”Miden distribuciones, normalmente latencias. No solo te dicen que una petición tardó 200ms, sino que agrupan las peticiones en “cubetas” (ej: 50 peticiones tardaron < 100ms, 10 tardaron < 500ms).
Histogramas: Se utilizan para ver distribuciones estadísticas.
Resúmenes: funcionan como los histogramas pero solamente te dan el valor total.
Por ejemplo, nos pueden dar la mediana o máximo o mínimo de por ejemplo el uso de la CPU.
Métricas disponibles
Section titled “Métricas disponibles”
Encontramos diferentes tipos de métricas:
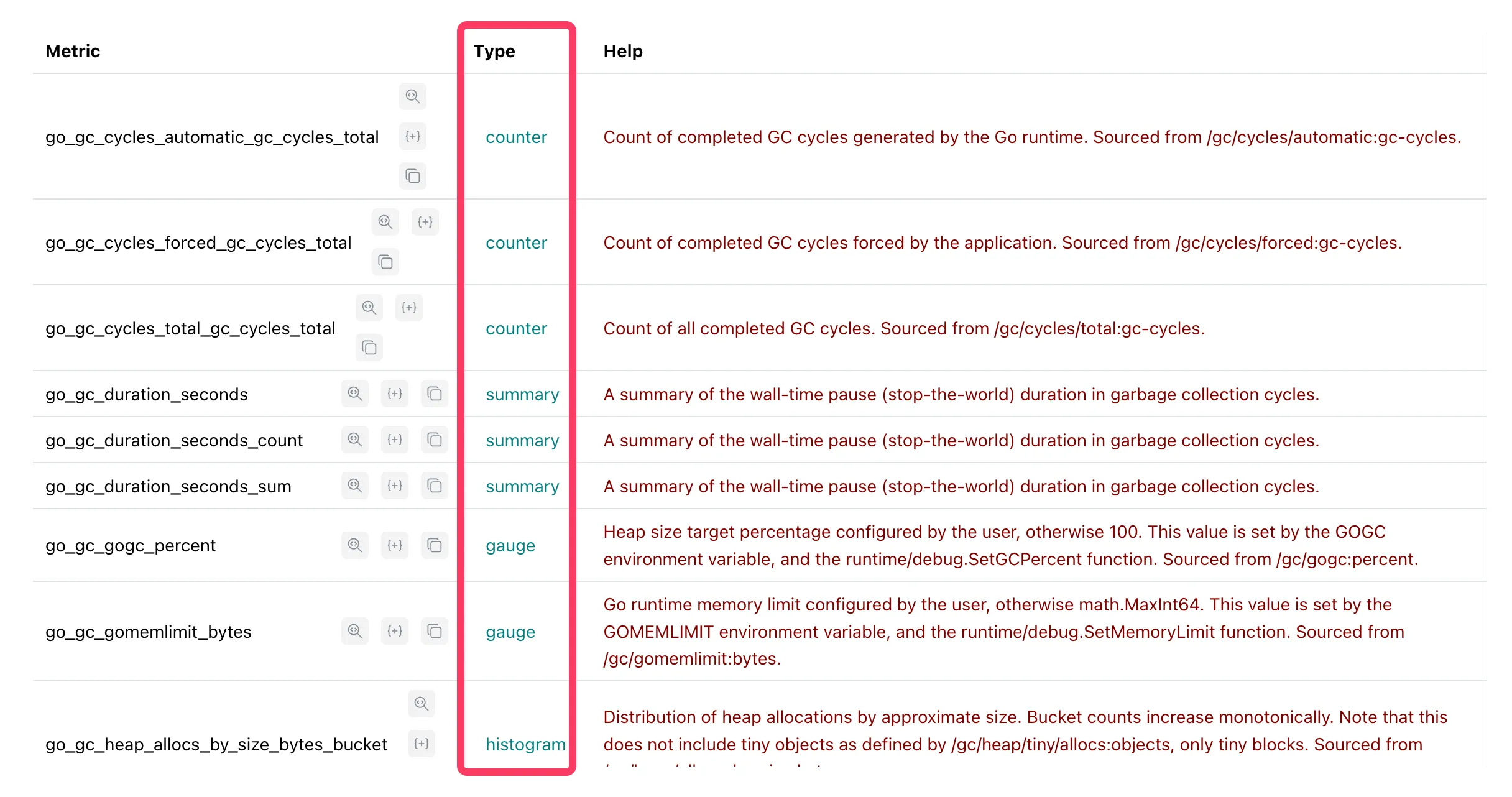
Ejemplos de consultas que podemos realizar:
Intervalos entre los diferentes “scrapeos”
prometheus_target_interval_length_seconds
Si estamos interesados en las de 0.99, las podemos filtrar con:
prometheus_target_interval_length_seconds{quantile="0.99"}
En graph:
rate(prometheus_tsdb_head_chunks_created_total[1m])`
cadvisor
Section titled “cadvisor”https://www.apptio.com/topics/kubernetes/devops-tools/cadvisor/
cAdvisor es un software de Google, escrito en Go, y programado específicamente para la captura de métricas de contenedores; necesita acceso a varios directorios del host (que mapearemos con bind-mounts en Docker) para capturar los datos. cAdvisor expone el puerto 8080 (interfaz web y REST api) y por defecto permite a Prometheus acceder a varias métricas.
cadvisor: http://localhost:8080/
cadvisor metrics: http://localhost:8080/metrics
Podemos consultar métricas como:
cadvisor_version_info
container_start_time_seconds{name="cadvisor"}
| rate(container_cpu_usage_seconds_total{name=“redis”}[1m]) | The cgroup’s CPU usage in the last minute | The redis container |
|---|---|---|
| container_memory_usage_bytes{name=“redis”} | The cgroup’s total memory usage (in bytes) | The redis container |
| rate(container_network_transmit_bytes_total[1m]) | Bytes transmitted over the network by the container per second in the last minute | All containers |
| rate(container_network_receive_bytes_total[1m]) | Bytes received over the network by the container per second in the last minute | All containers |
prometheus-node-exporter
Section titled “prometheus-node-exporter”https://elpuig.xeill.net/Members/vcarceler/articulos/monitorizacion-con-prometheus-y-grafana
Cada equipo, o aplicación, que vaya a ser monitorizado con Prometheus debe publicar sus propias métricas mediante HTTP para que Prometheus las recoja.
Para monitorizar un ordenador con GNU/Linux la opción más sencilla consiste en instalar prometheus-node-exporter que se ejecutará como un servicio y publicará las métricas en el puerto 9100 del ordenador.
3. PromQL: El lenguaje de las respuestas
Section titled “3. PromQL: El lenguaje de las respuestas”PromQL es el motor de búsqueda de Prometheus. Es extremadamente potente para operar con series temporales.
Filtrado con Etiquetas (Labels)
Section titled “Filtrado con Etiquetas (Labels)”Las etiquetas son el “DNI” de las métricas. Nos permiten ser específicos:
-- ❌ Demasiado genérico: CPU de todo el mundonode_cpu_seconds_total
-- ✅ Específico: Tiempo de CPU en modo "idle" (inactivo) para un servidor concretonode_cpu_seconds_total{mode="idle", instance="node-exporter:9100"}Funciones que debes conocer
Section titled “Funciones que debes conocer”| Función | Tipo | Analogía |
|---|---|---|
rate([5m]) | Counter | ¿A qué velocidad vamos ahora? (Media de 5 min) |
increase([1h]) | Counter | ¿Cuánto hemos recorrido en la última hora? |
avg_over_time([10m]) | Gauge | ¿Cuál ha sido el nivel medio de gasolina en 10 min? |
sum by (label) | Agregación | Agrupar los resultados (ej: por contenedor) |
4. Práctica Guiada 1: Explorando el ecosistema
Section titled “4. Práctica Guiada 1: Explorando el ecosistema”Tu entorno ya está activo. Vamos a verificar qué tenemos.
Paso 1: El estado de salud (Targets)
Section titled “Paso 1: El estado de salud (Targets)”Entra en la interfaz de Prometheus: http://localhost:9090 y navega a Status -> Targets.
Deberías ver una lista de “objetivos” en verde:
prometheus: Se monitoriza a sí mismo.node-exporter: Métricas de tu máquina virtual/host.cadvisor: Métricas de tus contenedores Docker.
Paso 2: Tu primera consulta (Métricas del Host)
Section titled “Paso 2: Tu primera consulta (Métricas del Host)”En la pestaña Graph, escribe y ejecuta:
-- Memoria RAM libre en GBnode_memory_MemAvailable_bytes / 1024 / 1024 / 1024Paso 3: Monitorizando Contenedores (cAdvisor)
Section titled “Paso 3: Monitorizando Contenedores (cAdvisor)”¿Cuánto consume tu base de datos o tu servidor web?
-- Uso de CPU por contenedor (en % de un core)-- Usamos 'image' para agruparsum by (image) (rate(container_cpu_usage_seconds_total{image!=""}[5m])) * 1005. El archivo de configuración prometheus.yml
Section titled “5. El archivo de configuración prometheus.yml”Aunque el sistema ya funciona, es importante entender cómo le hemos dicho a Prometheus dónde buscar información:
scrape_configs: - job_name: "node-exporter" static_configs: - targets: ["node-exporter:9100"]
- job_name: "cadvisor" static_configs: - targets: ["cadvisor:8080"]6. Práctica Guiada 2: Instrumentando tu propia APP (Python)
Section titled “6. Práctica Guiada 2: Instrumentando tu propia APP (Python)”Hasta ahora has visto métricas que otros han creado por ti. ¿Pero qué pasa si quieres medir el rendimiento de tu propio código? Vamos a crear un pequeño servicio en Python que genera métricas personalizadas.
Paso 1: Instalar la librería
Section titled “Paso 1: Instalar la librería”Necesitarás la librería oficial de Prometheus para Python:
pip install prometheus_clientPaso 2: Crear el script (monitor_app.py)
Section titled “Paso 2: Crear el script (monitor_app.py)”Crea un archivo con el siguiente código. Este script simula un proceso que recibe peticiones y aumenta un contador.
from prometheus_client import start_http_server, Counterimport timeimport random
# Definimos nuestra propia métrica: un Counter# Los nombres suelen seguir el patrón: nombre_servicio_unidades_totalPEDIDOS_TOTAL = Counter('bda_app_pedidos_recibidos_total', 'Número total de pedidos en nuestra app')
if __name__ == '__main__': # Iniciamos un servidor web en el puerto 8000 para exponer las métricas start_http_server(8000) print("Métricas en http://localhost:8000")
while True: # Simulamos que llega un pedido aleatoriamente PEDIDOS_TOTAL.inc() print("Nuevo pedido registrado!") time.sleep(random.uniform(1, 5))Ejecuta el script: python monitor_app.py. Ahora puedes entrar en http://localhost:8000 y verás tu métrica bda_app_pedidos_recibidos_total.
Paso 3: Decírselo a Prometheus
Section titled “Paso 3: Decírselo a Prometheus”Ahora hay que configurar al “Inspector” para que visite tu nueva app. Como Prometheus está en Docker y tu app está en tu host (Mac), usaremos la dirección especial host.docker.internal.
Modifica el archivo src/content/docs/modulo03/docker/prometheus.yml y añade este nuevo job:
# Tu nueva aplicación de pedidos - job_name: "mi-app-python" static_configs: - targets: ["host.docker.internal:8000"]Paso 4: Reiniciar Prometheus
Section titled “Paso 4: Reiniciar Prometheus”Para que coja los cambios, reinicia el contenedor:
docker compose restart prometheusVerificación: Ve a Prometheus -> Status -> Targets. Deberías ver mi-app-python en verde. Ahora puedes hacer un rate(bda_app_pedidos_recibidos_total[1 m]) y verás la velocidad de pedidos en tiempo real en la pestaña Graph.
Interpretando los resultados
Section titled “Interpretando los resultados”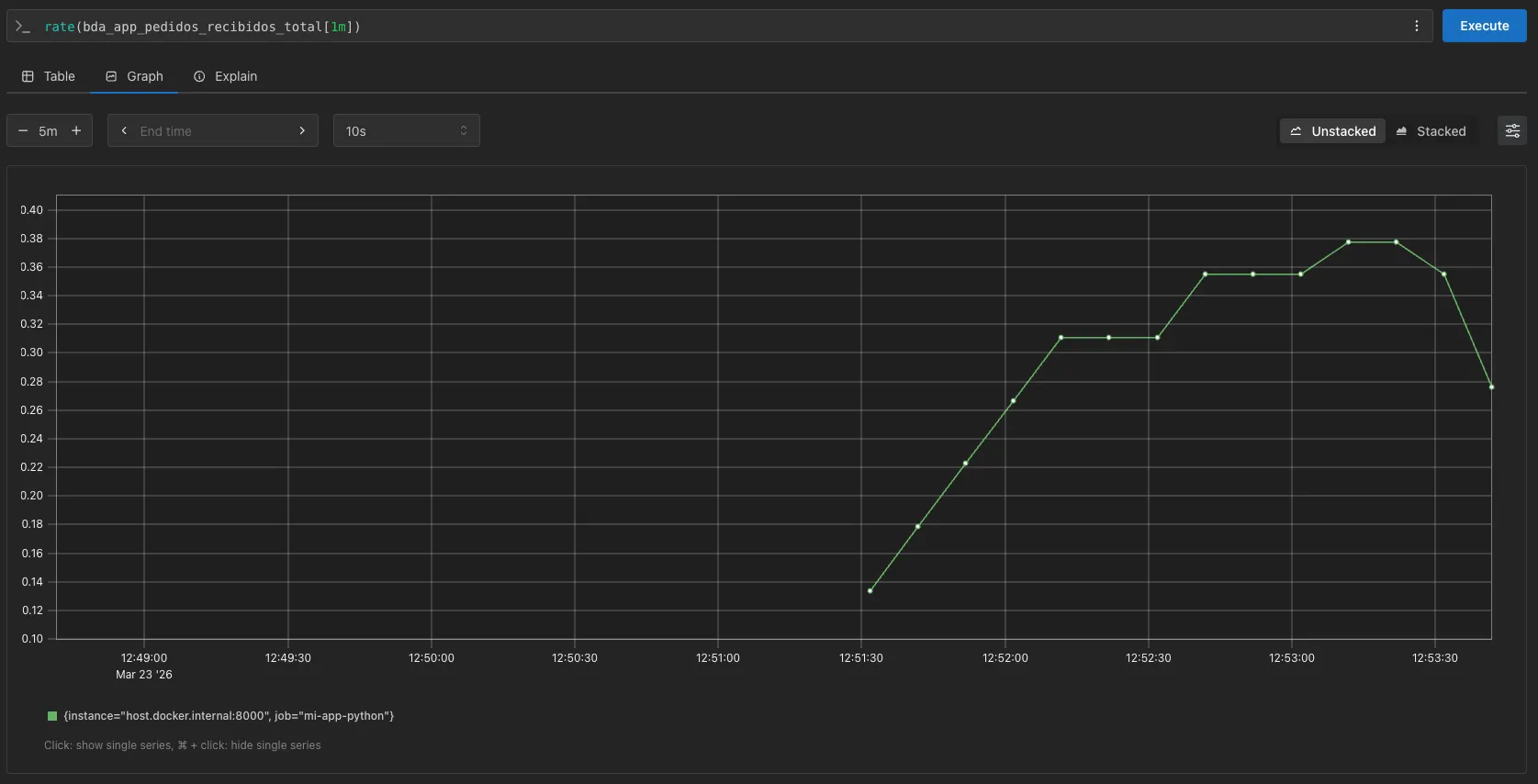
Cuando analizamos la gráfica de una función rate(), estamos viendo el caudal (throughput) de nuestra aplicación. En la imagen superior podemos observar:
- Pendiente inicial: Representa el momento en que la aplicación arranca y el “Inspector” (Prometheus) empieza a promediar los primeros datos.
- Mesetas (Plateaus): Los tramos llanos (como el nivel
0.30o0.36) indican que el tráfico es estable; la aplicación está procesando un número constante de pedidos por segundo. - Variación: Si los números suben o bajan, reflejan directamente los cambios en el
time.sleep()de tu script de Python o un aumento en la carga de trabajo. - Unidades: El eje Y representa peticiones por segundo (req/s). Un valor de
0.38significa que estamos recibiendo un pedido aproximadamente cada 2.6 segundos.
7. Alertas
Section titled “7. Alertas”Hasta ahora has sido un observador pasivo. Las métricas son datos históricos bonitos, pero ¿qué pasa cuando algo sale mal a las 3 AM?
Alertmanager es tu guardaespaldas. No solo detecta problemas, sino que elige cómo avisarte: Slack, email, PagerDuty, SMS… Sin él, podrías tener tu base de datos colapsada mientras duermes tranquilamente observando gráficas.
7.1 Arquitectura: Alertas en Acción
Section titled “7.1 Arquitectura: Alertas en Acción”graph LR P["Prometheus<br/>(Evalúa Rules)"] AR["Alert Rules<br/>(.yml)"] AM["AlertManager<br/>(Routing & Notificación)"] CH["Canales"]
P -- "Lee cada 30s" --> AR P -- "Si la alerta se activa..." --> AM AM -- "Agrupa & Enruta" --> CH CH --> Email["📧 Email"] CH --> Slack["💬 Slack"] CH --> PD["🚨 PagerDuty"] CH --> Webhook["🔗 Webhook Custom"]
style P fill:#e3f2fd,stroke:#1976d2,stroke-width:2px style AM fill:#ffccbc,stroke:#d84315,stroke-width:2px style AR fill:#f3e5f5,stroke:#7b1fa2,stroke-width:2px7.2 Alert Rules: Definiendo las Condiciones Críticas
Section titled “7.2 Alert Rules: Definiendo las Condiciones Críticas”Las Alert Rules son pequeños “si-entonces” que monitorean tus métricas. Se definen en archivos YAML y Prometheus las evalúa constantemente.
Estructura Básica de una Alert Rule
Section titled “Estructura Básica de una Alert Rule”groups: - name: "aplicacion" interval: 30s # Evalúa cada 30 segundos rules:
# Alerta 1: CPU muy alta - alert: CPUAlta expr: (100 - (avg by(instance) (irate(node_cpu_seconds_total{mode="idle"}[5m])) * 100)) > 80 for: 5m # Solo alerta si dura más de 5 minutos labels: severity: "warning" annotations: summary: "CPU > 80% en {{ $labels.instance }}" description: "La CPU ha superado el 80% durante 5 minutos. Valor actual: {{ $value }}%"
# Alerta 2: Memoria crítica - alert: MemoriaCritica expr: (node_memory_MemAvailable_bytes / node_memory_MemTotal_bytes) * 100 < 10 for: 2m labels: severity: "critical" annotations: summary: "RAM < 10% disponible" description: "Solo quedan {{ $value }}% de memoria libre. ¡Actúa ya!"
# Alerta 3: Disco lleno - alert: DiscoLleno expr: (node_filesystem_avail_bytes{mountpoint="/"} / node_filesystem_size_bytes{mountpoint="/"}) * 100 < 15 for: 10m labels: severity: "warning" annotations: summary: "Disco raíz apenas {{ $value }}% libre" description: "El disco está casi lleno. Necesitas limpiar espacio pronto."
# Alerta 4: Contenedor usando mucha memoria - alert: ContenedorMemoriaAlta expr: container_memory_usage_bytes{name!="cadvisor"} / 1073741824 > 1 # > 1 GB for: 3m labels: severity: "warning" servicio: "{{ $labels.name }}" annotations: summary: "Contenedor {{ $labels.name }} usa {{ $value }}GB" description: "El contenedor {{ $labels.name }} está consumiendo más de 1GB de RAM."
# Alerta 5: Target DOWN (exportador no responde) - alert: PrometheusTargetDown expr: up == 0 for: 1m labels: severity: "critical" annotations: summary: "Target {{ $labels.job }} DOWN" description: "El exporter {{ $labels.instance }} no responde desde hace 1 minuto."
# Alerta 6: Tasa de errores de aplicación - alert: TasaErroresAlta expr: rate(bda_app_errores_total[5m]) > 0.1 # > 0.1 errores/seg for: 5m labels: severity: "warning" annotations: summary: "Aplicación generando errores" description: "{{ $value }} errores/segundo en los últimos 5 minutos."7.3 Sintaxis Clave en Alert Rules
Section titled “7.3 Sintaxis Clave en Alert Rules”| Campo | Obligatorio | Explicación |
|---|---|---|
alert | ✅ Sí | Nombre de la alerta (sin espacios, snake_case) |
expr | ✅ Sí | Expresión PromQL que dispara la alerta |
for | ❌ No | Esperar X tiempo antes de activar (evita falsos positivos) |
labels | ❌ No | Etiquetas personalizadas para organizar/rutear alertas |
annotations | ❌ No | Mensajes humanizados (summary, description) |
7.4 Variables Dinámicas en Anotaciones
Section titled “7.4 Variables Dinámicas en Anotaciones”Dentro de {{ }} puedes usar variables:
annotations: summary: "CPU > 80% en {{ $labels.instance }}" description: "Valor actual: {{ $value }}% | Job: {{ $labels.job }}"{{ $labels.nombre_etiqueta }}: Accede a cualquier etiqueta de la métrica{{ $value }}: El valor numérico que disparó la alerta{{ $labels.instance }},{{ $labels.job }}: Labels estándar de Prometheus
7.5 Alertmanager: Ruteo y Notificaciones
Section titled “7.5 Alertmanager: Ruteo y Notificaciones”El Alertmanager recibe las alertas de Prometheus y decide a quién avisarle y cómo. Es como un recepcionista que entiende prioridades.
Archivo de Configuración: alertmanager.yml
Section titled “Archivo de Configuración: alertmanager.yml”global: resolve_timeout: 5m # Parámetros globales para email SMTP smtp_smarthost: 'smtp.gmail.com:587' smtp_auth_username: 'tu_email@gmail.com' smtp_auth_password: 'tu_app_password' # ⚠️ Usa variables de entorno en producción
# Define el receptor por defectoroute: receiver: 'default' group_by: ['alertname', 'cluster', 'service'] # Agrupa alertas similares group_wait: 10s # Espera 10s antes de enviar (agrupa alertas cercanas) group_interval: 10m # Reenvía cada 10m si la alerta persiste repeat_interval: 12h # Re-notifica cada 12h si aún está activa
# Rutas especiales para alertas críticas routes: - match: severity: critical receiver: 'oncall' group_wait: 0s # ¡INMEDIATO para críticas! repeat_interval: 30m
- match: severity: warning receiver: 'slack' group_wait: 5m repeat_interval: 4h
# Receptores: dónde se envían las alertasreceivers: - name: 'default' email_configs: - to: 'ops@empresa.com' from: 'alertas@empresa.com' smarthost: 'smtp.gmail.com:587' auth_username: 'alertas@empresa.com' auth_password: 'contraseña' headers: Subject: '[Prometheus] {{ .GroupLabels.alertname }}'
- name: 'oncall' pagerduty_configs: - service_key: 'YOUR_PAGERDUTY_KEY' description: '{{ .GroupLabels.alertname }}' email_configs: - to: 'oncall@empresa.com'
- name: 'slack' slack_configs: - api_url: 'https://hooks.slack.com/services/YOUR/SLACK/WEBHOOK' channel: '#alertas' title: '🚨 {{ .GroupLabels.alertname }}' text: '{{ range .Alerts }}{{ .Annotations.summary }}\n{{ end }}' send_resolved: true
# Inhibición: suprime alertas menos importantes si hay otras activasinhibit_rules: # Si el host está DOWN, no alertes por métricas de ese host - source_match: severity: 'critical' alertname: 'PrometheusTargetDown' target_match_re: severity: 'warning|info' equal: ['instance']Jerarquía de Rutas
Las rutas actúan como un árbol de decisiones. La primera coincidencia gana. Por eso las alertas críticas van arriba.
7.6 Práctica: Activar tu primera alerta
Section titled “7.6 Práctica: Activar tu primera alerta”Paso 1: Crear el archivo de rules
Section titled “Paso 1: Crear el archivo de rules”Crea src/content/docs/modulo03/docker/prometheus_rules.yml:
groups: - name: "ejercicio_alertas" interval: 15s rules: - alert: MemoriaDisponibleBaja expr: (node_memory_MemAvailable_bytes / 1024 / 1024 / 1024) < 1.5 for: 2m labels: severity: "warning" annotations: summary: "Memoria disponible < 1.5 GB" description: "Quedan {{ $value | humanize }}GB disponibles"Paso 2: Actualizar prometheus.yml
Section titled “Paso 2: Actualizar prometheus.yml”Añade al archivo de config de Prometheus:
rule_files: - "/etc/prometheus/prometheus_rules.yml"
alerting: alertmanagers: - static_configs: - targets: ["alertmanager:9093"]Paso 3: Reiniciar servicios
Section titled “Paso 3: Reiniciar servicios”docker compose restart prometheus alertmanagerPaso 4: Verificar en interfaz
Section titled “Paso 4: Verificar en interfaz”- Ve a Prometheus → Alerts: Verás tus reglas y su estado
- Ve a AlertManager → http://localhost:9093: Mira las alertas activas
7.7 Buenas Prácticas de Alertas
Section titled “7.7 Buenas Prácticas de Alertas”✅ DO’s:
- Nombra alertas en PascalCase:
CPUAlta,MemoriaCritica - Usa
for:para evitar ruido: no alertes por 30 segundos de CPU alta - Haz anotaciones descriptivas: ayuda a tu compañero a las 3 AM
- Severidades realistas:
criticalsolo para emergencias reales - Agrupa alertas relacionadas: no recibas 50 emails por el mismo problema
❌ DON’Ts:
- No alertes por todo: “La RAM cambió” no es una alerta
- No uses
severity: criticalpara warnings - No olvides incluir
{{ $value }}en las anotaciones - No ignores las alertas silenciadas (mute silence rules)
7.8 Silenciamiento Temporal de Alertas
Section titled “7.8 Silenciamiento Temporal de Alertas”A veces necesitas mantenimiento y no quieres alertas:
# Silenciar todas las alertas de un job por 2 horasamtool alert add job=node-exporter duration=2h comment="Mantenimiento planificado"
# Ver silencios activosamtool silence queryO desde la interfaz de AlertManager: Alerts → Silence
Errores Comunes y Troubleshooting
Section titled “Errores Comunes y Troubleshooting”- “Target is DOWN”: El contenedor del exporter no está funcionando o hay un problema de red entre Prometheus y el exporter. Revisa
docker compose ps. - Consulta sin resultados: Verifica que has escrito bien las etiquetas. PromQL distingue entre mayúsculas y minúsculas.
- Grafana no conecta: Asegúrate de que, al añadir Prometheus como Data Source en Grafana, usas la URL
http://prometheus:9090(nombre interno de Docker). - Las alertas no se disparan: Comprueba que
rule_filesestá enprometheus.ymly que Alertmanager está conectado enalerting. Revisa los logs:docker compose logs prometheus. - No recibo notificaciones: Verifica que AlertManager está running (
docker compose ps), que el receptor está correctamente configurado (email SMTP, Slack webhook, etc.) y que las alertas aparecen enhttp://localhost:9093.
Ejercicios
Section titled “Ejercicios”[!NOTE] Soluciones Las soluciones a estos ejercicios están en 1.Prometheus_SOL.txt
Ej. 1: El Inspector se monitoriza
Section titled “Ej. 1: El Inspector se monitoriza”Accede a Prometheus y busca la métrica prometheus_build_info.
- Reto: Identifica la versión exacta de Prometheus que estás ejecutando. ¿En qué etiqueta (label) se encuentra?
Ej. 2: El Pulso de la Máquina (Node Exporter)
Section titled “Ej. 2: El Pulso de la Máquina (Node Exporter)”Queremos saber qué tal va nuestro servidor.
- Reto: Escribe una consulta para obtener el porcentaje de espacio libre en disco en la partición raíz (
/). - Pista: Usa las métricas
node_filesystem_avail_bytesynode_filesystem_size_bytes.
Ej. 3: Tráfico de Red
Section titled “Ej. 3: Tráfico de Red”- Reto: Calcula la tasa de bytes recibidos por segundo (
node_network_receive_bytes_total) en los últimos 5 minutos para la interfazeth0. - Pista: Recuerda usar la función
rate().
Ej. 4: El Top 3 de Contenedores (cAdvisor)
Section titled “Ej. 4: El Top 3 de Contenedores (cAdvisor)”- Reto: Crea una consulta que devuelva los 3 contenedores que más memoria RAM están usando en este momento.
- Pista: Usa
topk(3, ...)y la métricacontainer_memory_usage_bytes.
Ej. 5: Diagnóstico Nginx (Profile Carga)
Section titled “Ej. 5: Diagnóstico Nginx (Profile Carga)”Si el generador de tráfico está activo, Nginx debería estar echando humo.
- Reto: Calcula la tasa de peticiones por segundo que está recibiendo Nginx.
- Métrica:
nginx_http_requests_total.
Ej. 6: Tu primera Alert Rule
Section titled “Ej. 6: Tu primera Alert Rule”Crea una alerta que se active cuando el uso de CPU en tu host supere el 50% durante 3 minutos.
- Pista: La métrica es
node_cpu_seconds_totalconmode="idle". Convierte a porcentaje. - Bonificación: Añade etiquetas de severidad y anotaciones descriptivas.
Ej. 7: Routing de Alertas en AlertManager
Section titled “Ej. 7: Routing de Alertas en AlertManager”Modifica alertmanager.yml para que las alertas de severidad critical se envíen a un canal diferente del default.
- Reto: Usa
match:para filtrar por severidad yreceiver:para elegir dónde enviarlas.
🚀 Proyecto: Tu Cuadro de Mandos Operativo
Section titled “🚀 Proyecto: Tu Cuadro de Mandos Operativo”Un buen ingeniero de datos nunca vuela a ciegas. Tu misión es definir un conjunto de consultas críticas para un dashboard de “Salud del Clúster”:
- CPU Host: % de uso total de CPU del servidor.
- RAM Host: % de RAM usada.
- Containers: Lista de contenedores activos agrupados por imagen.
count(container_last_seen) by (image)- Red: Ratio de errores de red en el host.
Alertas Prometheus - Ejemplos por Tecnología
Section titled “Alertas Prometheus - Ejemplos por Tecnología”Una colección lista para usar de Alert Rules organizadas por severidad y tecnología.
Cómo usar este documento
Section titled “Cómo usar este documento”Copia cualquier bloque - alert: que necesites y pégalo en tu prometheus_rules.yml:
groups: - name: "mi_infraestructura" interval: 30s rules: # Pega aquí cualquier alerta del documento🔴 ALERTAS CRÍTICAS (Severity: critical)
Section titled “🔴 ALERTAS CRÍTICAS (Severity: critical)”Estas requieren acción INMEDIATA. No admiten espera.
Host/Sistema Operativo
Section titled “Host/Sistema Operativo” - alert: HostDown expr: up{job="node-exporter"} == 0 for: 1m labels: severity: critical team: infraestructura annotations: summary: "Host {{ $labels.instance }} NO RESPONDE" description: "El servidor {{ $labels.instance }} no está alcanzable desde Prometheus" runbook: "https://wiki.empresa.com/host-down"
- alert: DiskCritical expr: (node_filesystem_avail_bytes{mountpoint="/"} / node_filesystem_size_bytes{mountpoint="/"}) * 100 < 5 for: 1m labels: severity: critical team: infraestructura annotations: summary: "⚠️ DISCO RAÍZ CRÍTICO: Solo {{ $value }}% libre" description: "El disco / tendrá espacio en menos de 1 hora si continúa escribiendo"
- alert: MemoriaAgotada expr: (node_memory_MemAvailable_bytes / node_memory_MemTotal_bytes) * 100 < 5 for: 2m labels: severity: critical team: infraestructura annotations: summary: "RAM < 5% disponible en {{ $labels.instance }}" description: "Queda {{ $value }}% de memoria. Riesgo de OOM Kill inminente."
- alert: SwapCritical expr: (node_memory_SwapFree_bytes / node_memory_SwapTotal_bytes) * 100 < 10 for: 1m labels: severity: critical annotations: summary: "Swap crítico: {{ $value }}% libre" description: "El área de swap está casi llena. Sistema en riesgo de colapso."
- alert: LoadAverage expr: node_load15 > (count by (instance) (node_cpu_seconds_total{mode="idle"}) * 4) for: 5m labels: severity: critical annotations: summary: "Load average crítico: {{ $value }}" description: "La carga del sistema es {{ $value }} veces el número de CPUs disponibles"Aplicaciones/Servicios
Section titled “Aplicaciones/Servicios” - alert: ServiceDown expr: up{job!="prometheus"} == 0 for: 2m labels: severity: critical component: "{{ $labels.job }}" annotations: summary: "{{ $labels.job }} está CAÍDO" description: "El servicio {{ $labels.job }} en {{ $labels.instance }} no responde"
- alert: ErrorRateHigh expr: rate(http_requests_total{status=~"5.."}[5m]) > 0.5 # > 0.5 errores/segundo for: 2m labels: severity: critical team: backend annotations: summary: "Tasa de errores 5xx: {{ $value }} req/s" description: "Tu aplicación está generando {{ $value | humanize }} errores por segundo. PÁGINA ROTA."
- alert: DatabaseConnectionPoolExhausted expr: mysql_global_status_max_used_connections / mysql_global_variables_max_connections > 0.9 for: 1m labels: severity: critical database: "{{ $labels.instance }}" annotations: summary: "Pool de conexiones BD al 90%" description: "Quedan {{ $value | humanizePercentage }} de conexiones disponibles"⚠️ ALERTAS DE AVISO (Severity: warning)
Section titled “⚠️ ALERTAS DE AVISO (Severity: warning)”Requieren atención, pero no es emergencia. Planificar acción en horas.
Host/Sistema Operativo
Section titled “Host/Sistema Operativo” - alert: HighCPUUsage expr: (100 - (avg by(instance) (irate(node_cpu_seconds_total{mode="idle"}[5m])) * 100)) > 80 for: 10m # Solo si persiste 10 minutos labels: severity: warning team: infraestructura annotations: summary: "CPU al {{ $value }}% en {{ $labels.instance }}" description: "La CPU ha estado por encima del 80% durante los últimos 10 minutos" grafana: "https://grafana.empresa.com/d/cpu-dashboard"
- alert: HighMemoryUsage expr: (1 - (node_memory_MemAvailable_bytes / node_memory_MemTotal_bytes)) * 100 > 85 for: 5m labels: severity: warning team: infraestructura annotations: summary: "RAM al {{ $value }}% en {{ $labels.instance }}" description: "El servidor {{ $labels.instance }} está usando {{ $value | humanize }}% de RAM"
- alert: DiskSpaceRunningOut expr: (node_filesystem_avail_bytes{mountpoint="/"} / node_filesystem_size_bytes{mountpoint="/"}) * 100 < 20 for: 30m labels: severity: warning team: infraestructura annotations: summary: "Disco: solo {{ $value }}% libre" description: "A este ritmo de escritura, se llena en {{ (node_filesystem_avail_bytes / (node_filesystem_avail_bytes - (node_filesystem_avail_bytes offset 1h))) * 100 | humanize }} horas"
- alert: HighIOWait expr: rate(node_cpu_seconds_total{mode="iowait"}[5m]) > 0.3 # > 30% tiempo esperando I/O for: 5m labels: severity: warning team: infraestructura annotations: summary: "IOWait al {{ $value | humanizePercentage }}" description: "El sistema está esperando operaciones de disco. Posible cuello de botella."
- alert: NetworkErrors expr: rate(node_network_receive_errs_total[5m]) > 0.01 or rate(node_network_transmit_errs_total[5m]) > 0.01 for: 5m labels: severity: warning interface: "{{ $labels.device }}" annotations: summary: "Errores de red en {{ $labels.device }}" description: "{{ $value }} errores por segundo en la interfaz {{ $labels.device }}"Contenedores Docker (cAdvisor)
Section titled “Contenedores Docker (cAdvisor)” - alert: ContainerMemoryWarning expr: (container_memory_usage_bytes / 1073741824) > 0.8 # > 0.8 GB for: 5m labels: severity: warning container: "{{ $labels.name }}" annotations: summary: "Contenedor {{ $labels.name }} usa {{ $value | humanize }}GB" description: "Este contenedor está consumiendo mucha memoria. Considera aumentar el límite."
- alert: ContainerRestartFrequent expr: rate(container_last_seen{name!="cadvisor"}[5m]) > 0.1 # Reinicia > cada 10 seg for: 2m labels: severity: warning container: "{{ $labels.name }}" annotations: summary: "Contenedor {{ $labels.name }} reiniciando frecuentemente" description: "El contenedor se ha reiniciado {{ $value }} veces en los últimos 5 minutos"
- alert: ContainerNetworkBandwidth expr: (rate(container_network_receive_bytes_total[1m]) + rate(container_network_transmit_bytes_total[1m])) / 1024 / 1024 > 100 # > 100 MB/s for: 5m labels: severity: warning container: "{{ $labels.name }}" annotations: summary: "Red saturada en {{ $labels.name }}: {{ $value | humanize }}MB/s" description: "Hay {{ $value | humanize }} MB/s de tráfico. Posible DOS o fuga de datos."Bases de Datos
Section titled “Bases de Datos” - alert: MySQLSlowQueries expr: rate(mysql_global_status_slow_queries[5m]) > 0.1 for: 5m labels: severity: warning database: "{{ $labels.instance }}" annotations: summary: "MySQL: {{ $value }} queries lentos/segundo" description: "Tu MySQL tiene {{ $value | humanize }} queries lentos por segundo"
- alert: MySQLReplication expr: mysql_slave_status_slave_io_running == 0 or mysql_slave_status_slave_sql_running == 0 for: 1m labels: severity: warning database: "{{ $labels.instance }}" annotations: summary: "Replicación MySQL caída" description: "La replicación en {{ $labels.instance }} se ha detenido"
- alert: RedisMemory expr: redis_memory_used_bytes / redis_memory_max_bytes > 0.9 for: 5m labels: severity: warning cache: "{{ $labels.instance }}" annotations: summary: "Redis: {{ $value | humanizePercentage }} de memoria usada" description: "Redis está al {{ $value | humanizePercentage }} de su límite. Aumenta maxmemory."
- alert: RedisEvictions expr: rate(redis_evicted_keys_total[5m]) > 0 for: 2m labels: severity: warning cache: "{{ $labels.instance }}" annotations: summary: "Redis: evinciones activas" description: "Redis está expulsando {{ $value | humanize }} keys/segundo"Aplicaciones Web
Section titled “Aplicaciones Web” - alert: HighLatency expr: histogram_quantile(0.95, rate(http_request_duration_seconds_bucket[5m])) > 1 # P95 > 1 segundo for: 5m labels: severity: warning team: backend annotations: summary: "Latencia P95: {{ $value | humanize }}s" description: "El 95% de las requests tardan más de {{ $value | humanize }}s"
- alert: HighErrorRate expr: rate(http_requests_total{status=~"5.."}[5m]) / rate(http_requests_total[5m]) > 0.05 # > 5% for: 5m labels: severity: warning service: "{{ $labels.job }}" annotations: summary: "Tasa de error: {{ $value | humanizePercentage }}" description: "{{ $value | humanizePercentage }} de las requests están fallando"
- alert: CertificateExpiring expr: ssl_cert_not_after - time() < 7 * 24 * 3600 # < 7 días for: 1m labels: severity: warning cert: "{{ $labels.domain }}" annotations: summary: "Certificado SSL expira en {{ ($value / 86400) | humanize }} días" description: "El certificado de {{ $labels.domain }} caduca en {{ ($value / 86400) | humanize }} días"ℹ️ ALERTAS INFORMATIVAS (Severity: info)
Section titled “ℹ️ ALERTAS INFORMATIVAS (Severity: info)”Útiles para alertas de auditoría, cambios planificados, etc. Bajo ruido.
- alert: ScheduledMaintenance expr: up > 0 # Placeholder - requiere activación manual for: 1m labels: severity: info team: operations annotations: summary: "Mantenimiento programado iniciado" description: "Sistema en ventana de mantenimiento: 02:00-04:00 UTC"
- alert: DailyBackupCompleted expr: rate(backup_duration_seconds[5m]) > 0 # Si hay actividad de backup for: 1m labels: severity: info annotations: summary: "Backup diario completado" description: "Backup de {{ $labels.database }} tardó {{ $value | humanize }}s"
- alert: LargeDeployment expr: rate(deployment_timestamp[1m]) > 0 for: 1m labels: severity: info service: "{{ $labels.service }}" annotations: summary: "Deploy de {{ $labels.service }} detectado" description: "Nueva versión {{ $labels.version }} desplegada"Plantilla Generic para crear tus propias alertas
Section titled “Plantilla Generic para crear tus propias alertas” - alert: NombreAlertaEnPascalCase expr: YOUR_PROMQL_QUERY_HERE for: 5m # Ajusta según sensitivity requerida labels: severity: warning # critical / warning / info team: nombre_equipo component: "{{ $labels.LABEL_IMPORTANTE }}" runbook: "https://wiki.empresa.com/alerts/nombre-alerta" annotations: summary: "[{{ $labels.severity | upper }}] Resumen corto del problema" description: "Descripción detallada: {{ $value | humanize }} + contexto desde labels" runbook_url: "https://wiki.empresa.com/runbooks/nombre-alerta" dashboard: "https://grafana.empresa.com/d/ID-dashboard"Funciones útiles para tus alertas
Section titled “Funciones útiles para tus alertas”# Conversiones{{ $value | humanize }} # 1500 → "1.5k"{{ $value | humanizePercentage }} # 0.95 → "95%"{{ ($value / 1024) }} # Convertir a KB desde bytes
# Comparacionesrate(metric[5m]) # Velocidad de cambioincrease(metric[1h]) # Cambio absoluto en 1htopk(3, metric) # Top 3 valores
# Agregacionessum by (label) # Suma por labelavg by (label) # Media por labelcount by (label) # Conteo por label
# Temporalesoffset 1h # Comparar con datos de hace 1hhistogram_quantile(0.95, ...) # Percentil 95Tips Profesionales
Section titled “Tips Profesionales”Timing de for:
Critical: 1-2 minutos (rápida respuesta)Warning: 5-10 minutos (evita ruido)Info: 15-30 minutos (muy tolerante)Label Naming
labels: severity: [critical, warning, info] # Obligatorio team: [backend, infraestructura, datos] runbook: "https://..." # Link a instruccionesAnotaciones
annotations: summary: "Línea 1 - Qué pasó" # < 80 chars description: "Línea 2+ - Por qué, contexto, valores" runbook: "Cómo arreglarlo"